普段はアプリケーションレイヤの仕事をしているため、「データベースはデータを入れておくただの箱」という発想でした。が、さすがにこれはまずいだろう、と思いたち、勉強中です。 とくにデータベースが専門領域というわけではないので、間違いがあれば教えてください。
検証バージョン
- PostgreSQL 10.5 自前ビルド
はじめに
PostgeSQL におけるデータの実態はファイル。 言うまでもないが、ディスクに書きこむことでデータを永続化する。
しかし、メモリと比較してディスクへの読み書きは非常に遅い。
参考 プログラマーが知っておくべき「PC内部の通信速度」
そのため、ディスクアクセスをできる限り減らして、より高速にアクセスできるメモリで処理しておき、ある程度まとめてディスクに書き出せば早いじゃないか。(No Force = コミット 時にディスクへ書き込まない。いつか誰かがやる。)
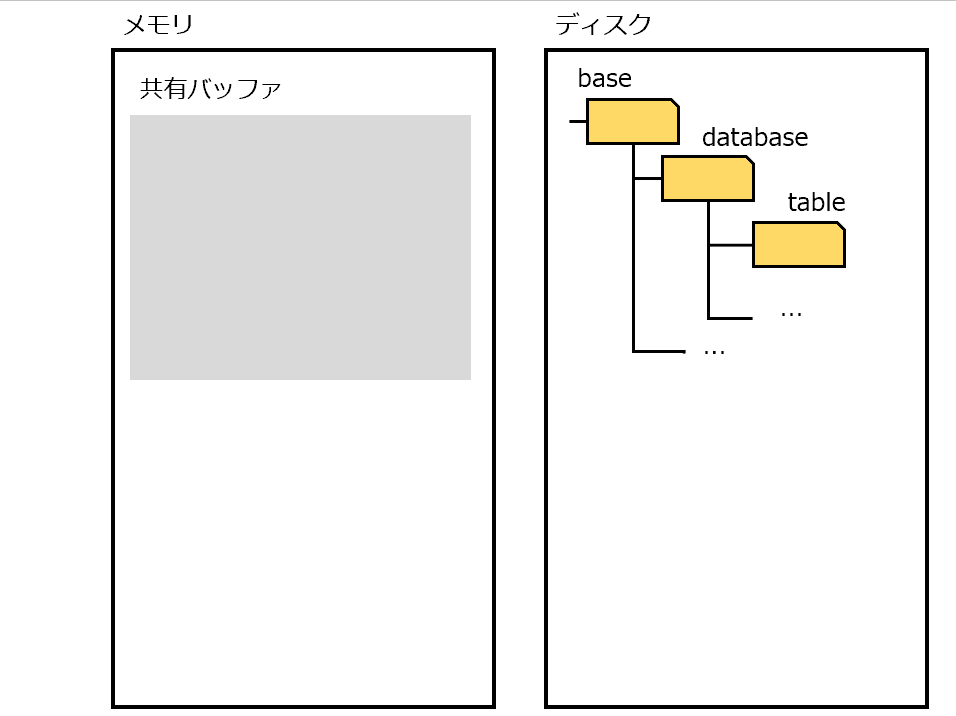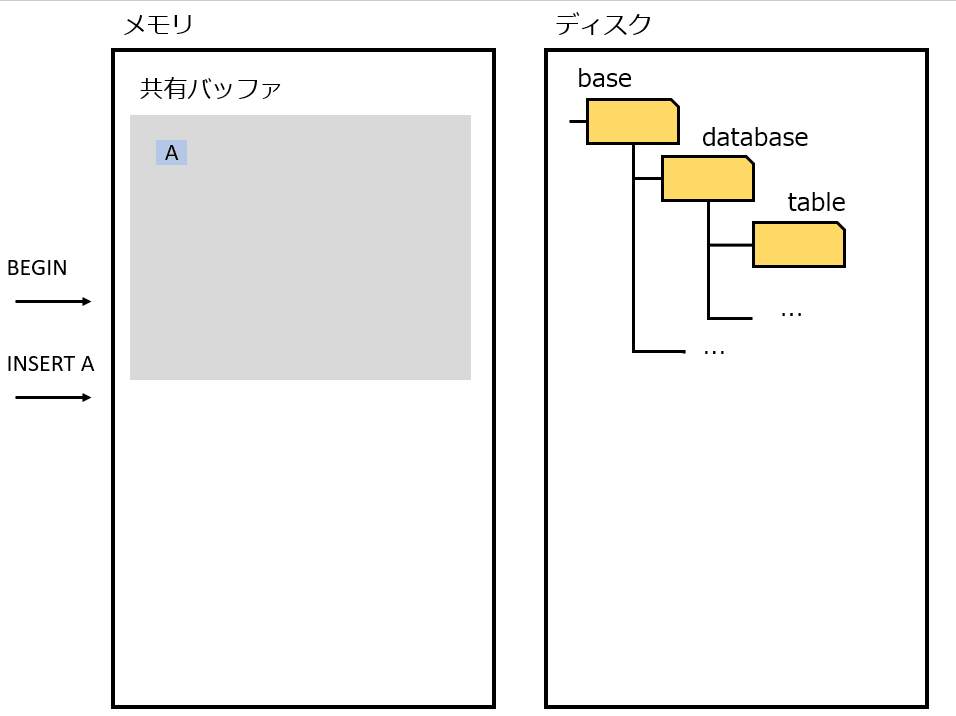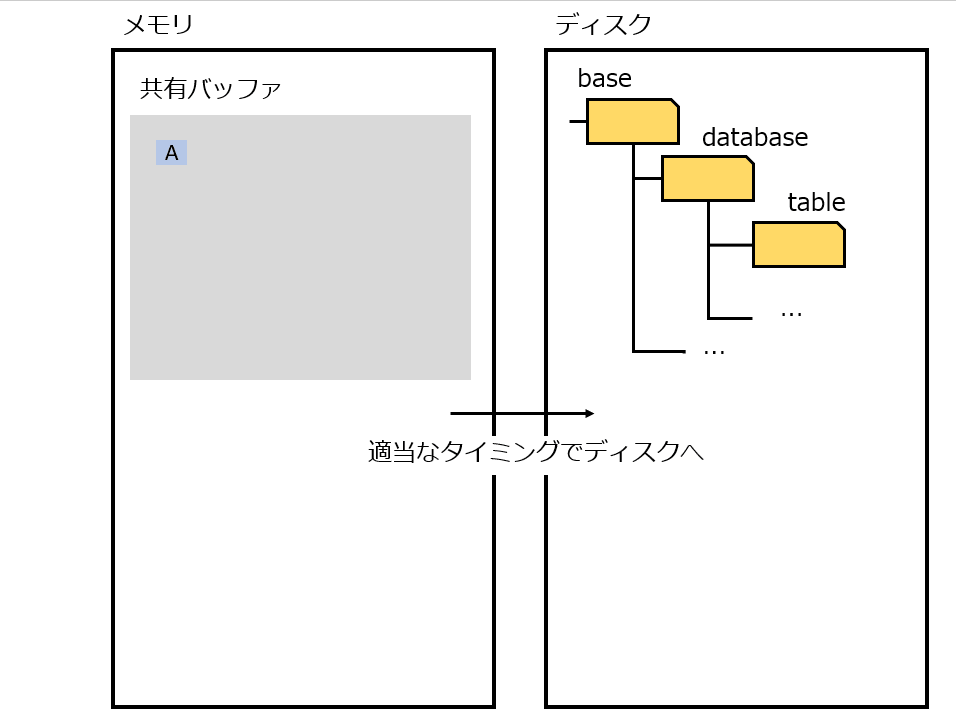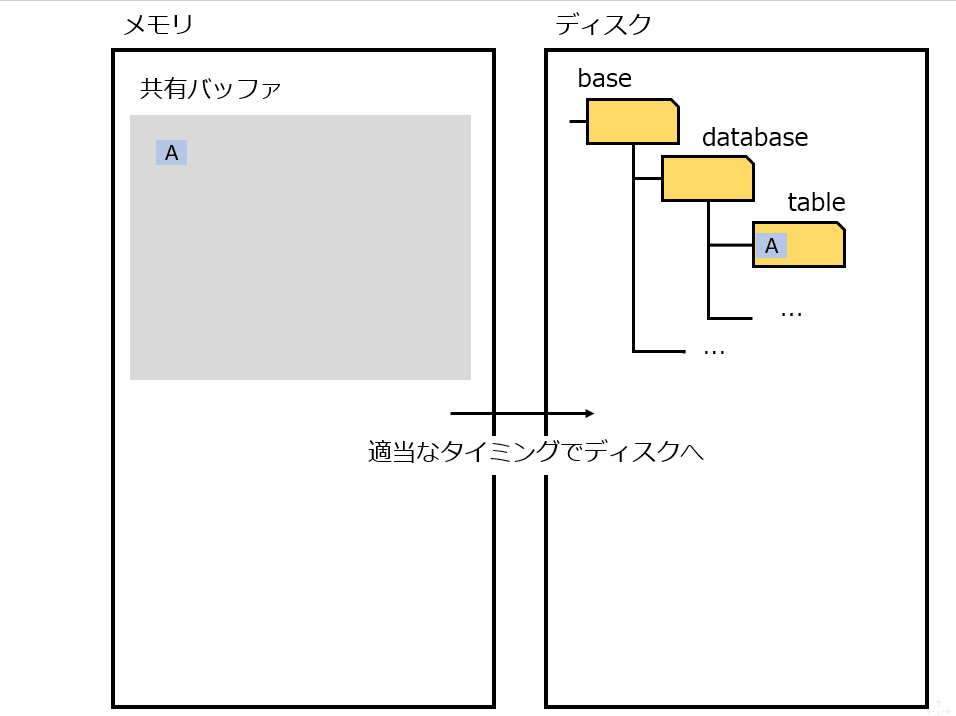
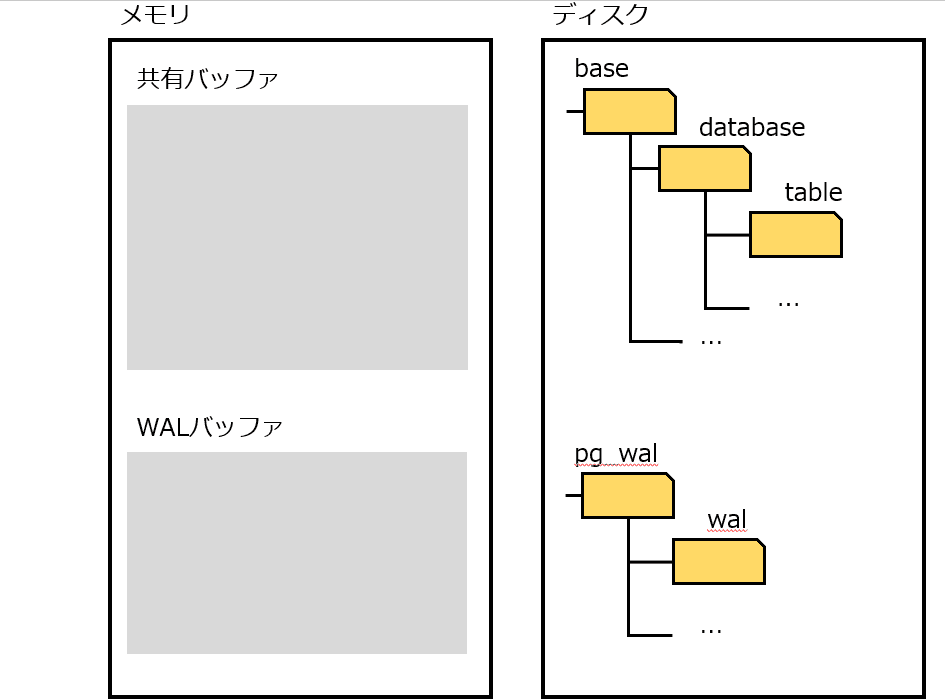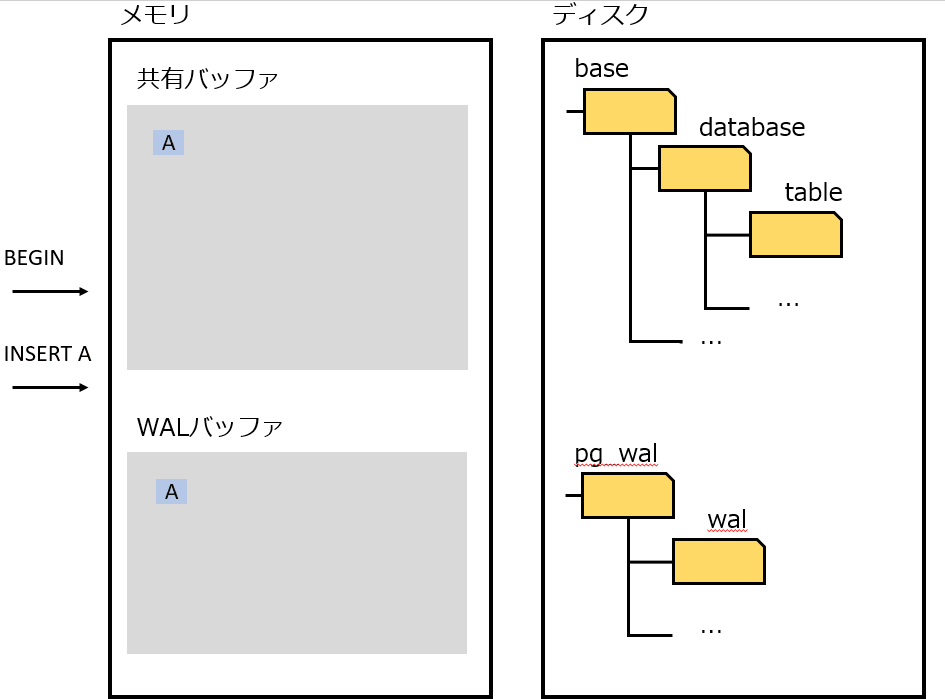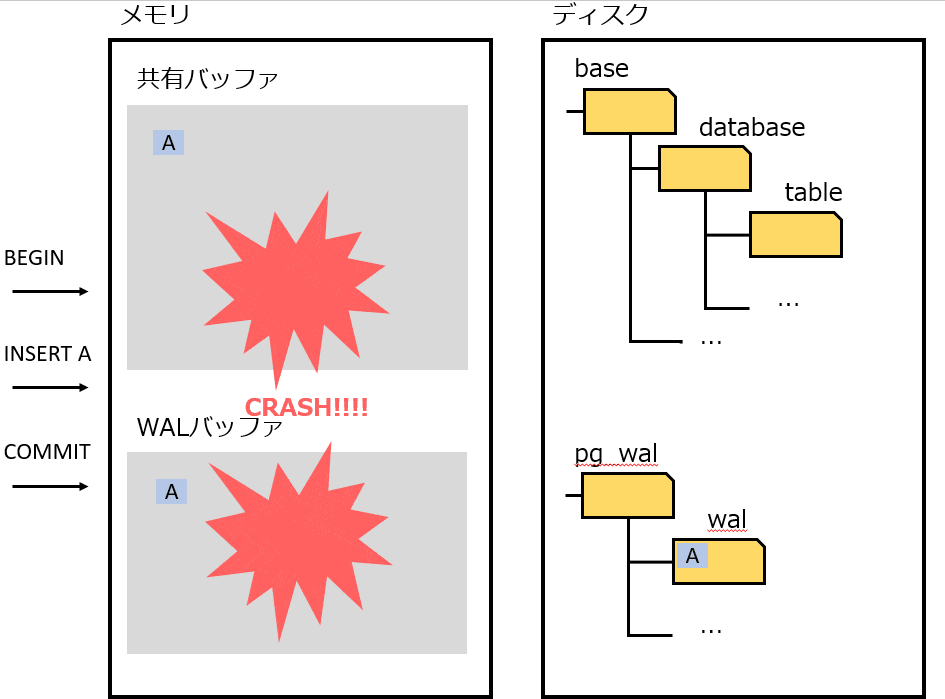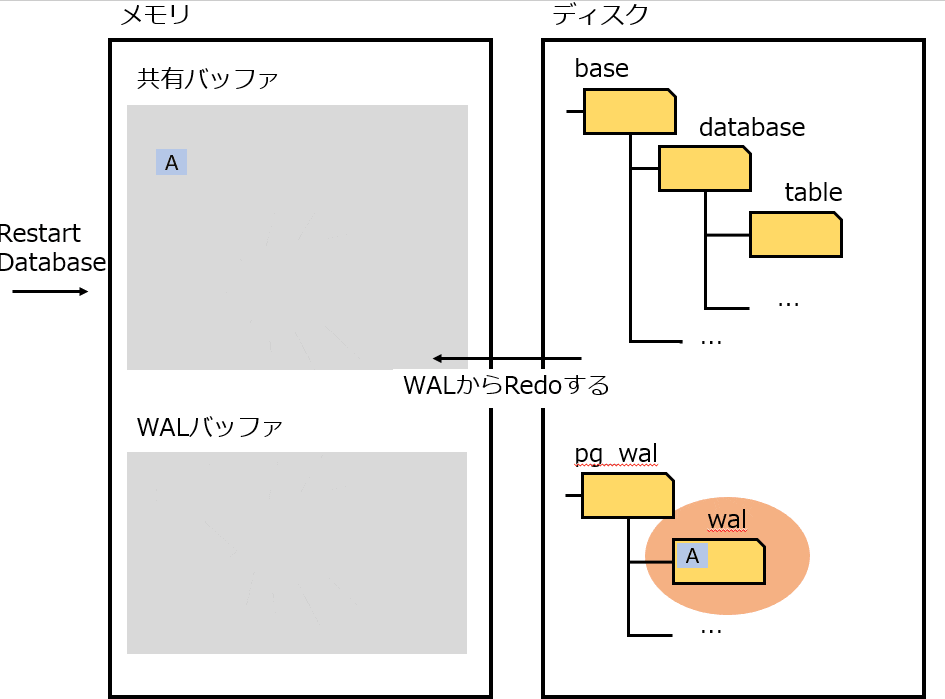
しかしこの仕組みは、故障時(プロセス故障、電源断)に困る。メモリに存在するデータをディスクに書き出す前に終了してしまうため、コミットしたはずのデータを失うことになる。
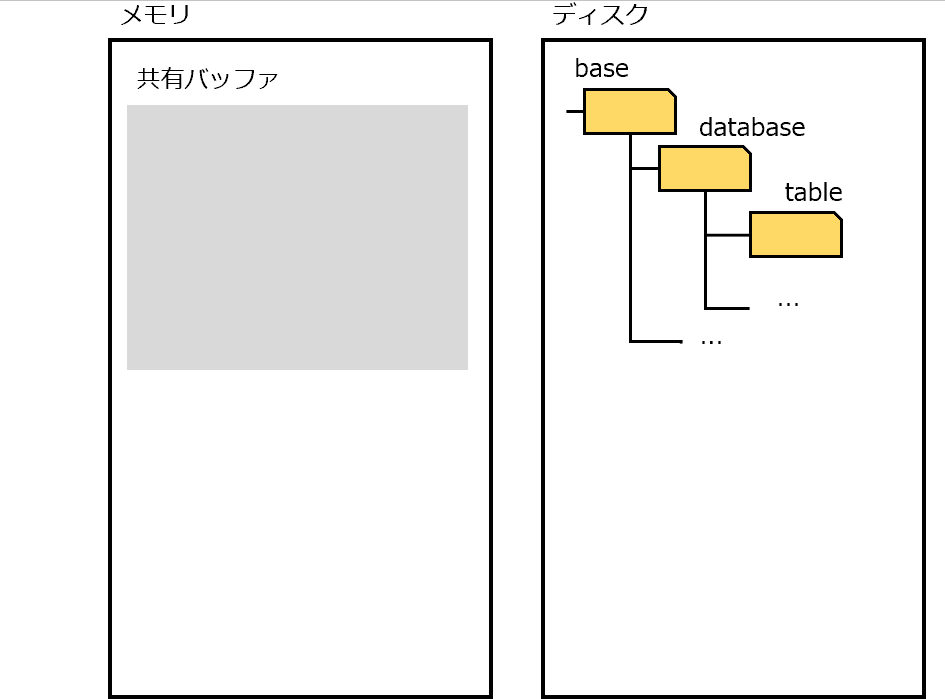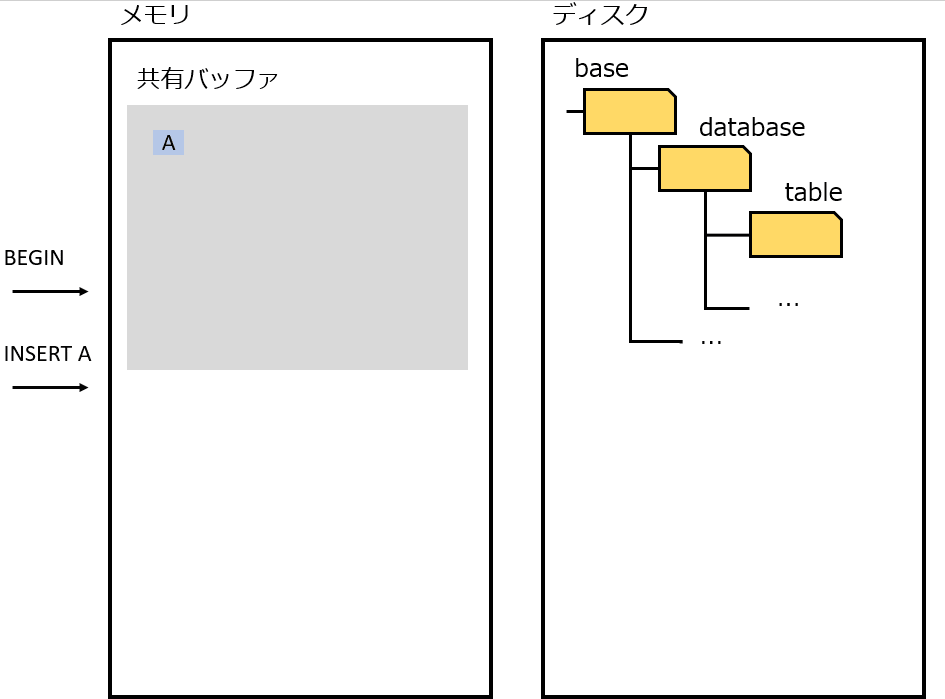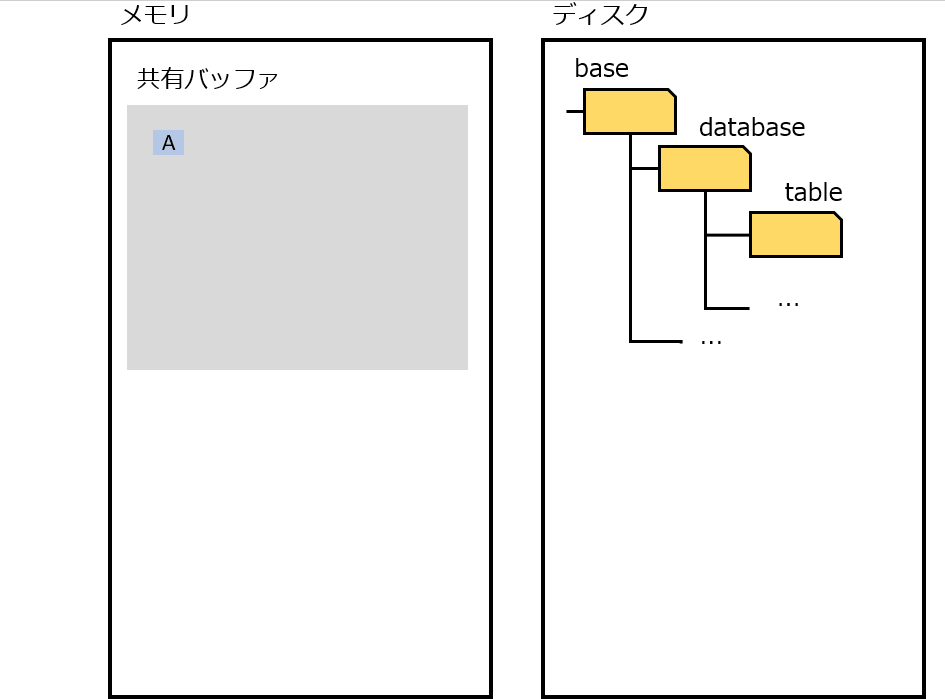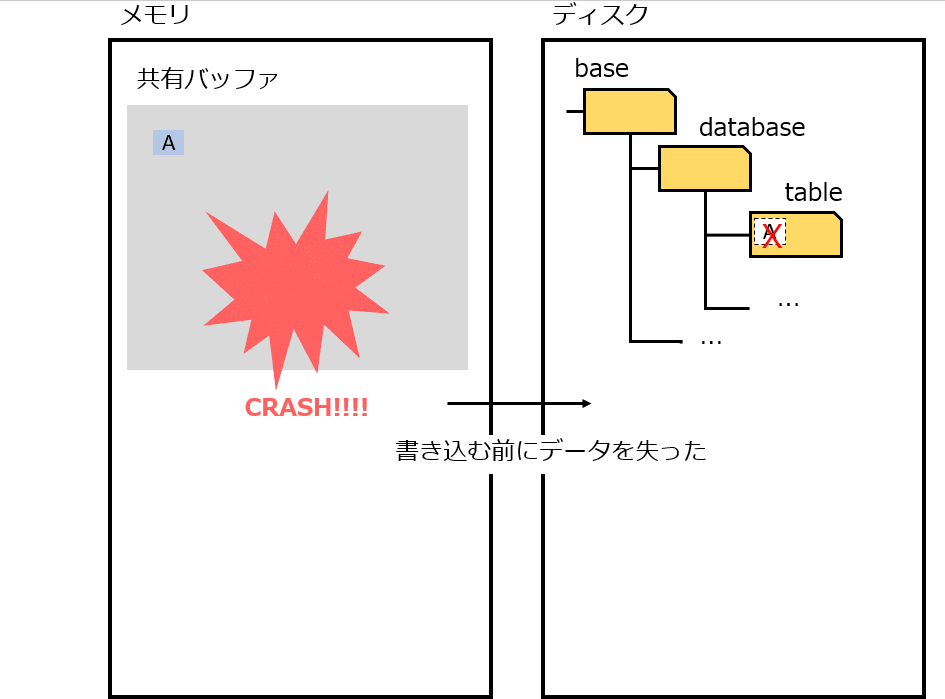
上記の問題(故障時のメモリとディスクの不一致)をなんとかするための仕組みが、 WAL(Write Ahead Log)。
WAL は、データを変更する前に、更新内容をログに記録する。これによって、クラッシュ時に WAL を利用することで、データの不整合を解消することができる。
WALもデータをディスクに書き出すならそのままデータを更新すればいいじゃないか、と思うが、ファイル末尾にアペンドするだけなので早い。(らしい。ランダムアクセスとシーケンシャルアクセスの違い。)
じゃあ、ディスクがメモリくらい高速になったとしたら WAL は不要になるか、というとそうではない。原子性の保証という点でも WAL には効果がある。
ディスクへの書き込み中に故障した場合、書き込みが中途半場な状態(新旧データが混じったような不整合な状態)になる。このとき、 WAL があれば、壊れたページを復旧することができる。詳細は 後述 する。
故障時に注意する点はもう一つある。
メモリは有限なので、共有バッファからあふれたデータはディスクに書き出したい。そうなると、コミットする前のデータをディスクに書き込む可能性がある。(Steal…コミットされてないデータもディスクに書き込まれる) そのため、通常のデータベースは、コミットされていないデータをリカバリ時に取り消し(UNDO)しなければいけない。
しかし、PostgreSQL では UNDO は必要ない。これは PostgreSQL が追記型アーキテクチャであり、複数バージョンのデータを保持しておいて、txごとの可視性で参照できるデータを切り替えているから(MVCC)。誰からも参照されないゴミデータは VACUUM によって処理される。
参考 Mvcc Unmasked
REDO/UNDO の詳細については、以下が参考になる。
参考 リレーショナルデータベースの仕組み (3/3)
参考 MIT ARIES講義資料
WAL には何を書くの?
pg_dumpwal コマンドで WAL のヘッダーを表示できる。
参考 pg_waldump
**WALログを識別するID(=LSN)**や、 REDO するのに必要な情報が含まれる。
REDO するのに必要な情報とは、以下のようなもの。
- どのリソースに対する操作か(HEAP, Transaction, Btreeなど)
- どんな操作か(INSERT, UPDATE, DELETE, COMMIT, ROLLBACK, INSERT_LEAFなど)
- どのTx内での操作か
- どのページへの操作か
また、 WAL のデータが壊れていないことを確認するために、 CRC 符号も付与される。
参考 Wikipedia 巡回冗長検査
詳細は 9.4. Internal Layout of XLOG Record を参照する。
]$ pg_waldump /tmp/sampledb/pg_wal/000000010000000000000003
rmgr: Heap len (rec/tot): 61/ 61, tx: 559, lsn: 0/03000028, prev 0/02000100, desc: INSERT off 4, blkref #0: rel 1663/13214/16384 blk 0
rmgr: Transaction len (rec/tot): 34/ 34, tx: 559, lsn: 0/03000068, prev 0/03000028, desc: COMMIT 2019-02-16 09:16:14.006604 JST
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/03000090, prev 0/03000068, desc: RUNNING_XACTS nextXid 560 latestCompletedXid 559 oldestRunningXid 560
LSN は操作ごとに単調増加する値であり、これによって操作の順番が把握できる。
LSN の番号体系は PostgreSQL WAL for DBAs や The Internals of PostgreSQL 9.2. Transaction Log and WAL Segment Files を参考にする。
WAL は、扱いやすいように1ファイル 16MB に分割される。また、アーカイブしなければ、オンラインリカバリに不要と判断されたものから削除/再利用される。 詳細は The Internals of PostgreSQL 9.9.2. WAL Segment Management in Version 9.5 or Later を参考にする。
WAL の書き込み
通常、書き込みを効率化するために、以下のようなキャッシュが利用される。
- OSのバッファキャッシュ
- RAIDコントローラキャッシュ
- ディスクコントローラキャッシュ
これらのキャッシュは、書き込み要求があったときに即座に完了を返す。その後、書き込み要求をまとめたり、順序を入れ替えることで効率化する。
参考 Linux I/O のお話 write 編
参考 RAIDコントローラのキャッシュ構成
しかし WAL では、実際にディスクに書き込まれていないにも関わらず、書き込みが完了したと通知されると、信頼性の観点から問題になる。(万が一 WAL がディスクに書き込めていないと WAL の前提が崩れる)
ディスクへの同期的な書き込みが保証されるシステムコール(fsync や fdatasync)が存在するため、OSレベルではこれらのシステムコールを利用する。(ファイルシステムのマウントオプションが async であっても、このシステムコールによって該当の書き込みは async が無視される。)
※ どのシステムコールを利用するかは、 fsync_method で指定できる。また、pg_test_fsync コマンドでベンチマークが取得できる。
RAIDコントローラキャッシュやディスクコントローラキャッシュは、電源断時も書き込みが保証できる(バッテリバックアップが付属している等)ならば write-back でも良いが、保証できないなら write-through を選ぶ必要がある。
参考 第30章 信頼性とログ先行書き込み 30.1. 信頼性
関連するプロセス
WAL に関連するプロセスの動作を理解する。
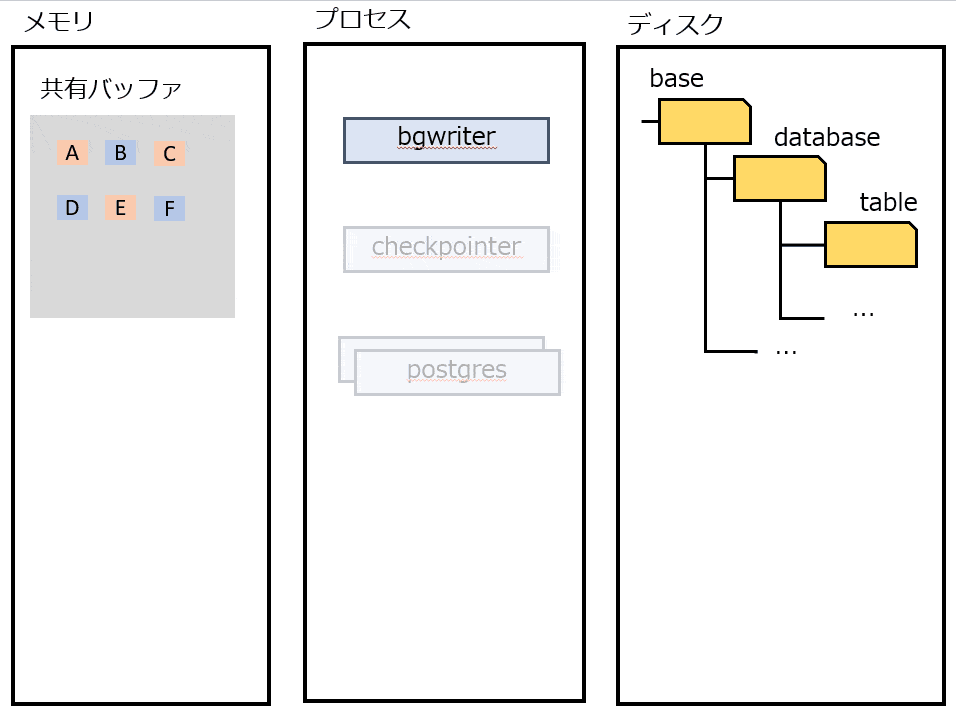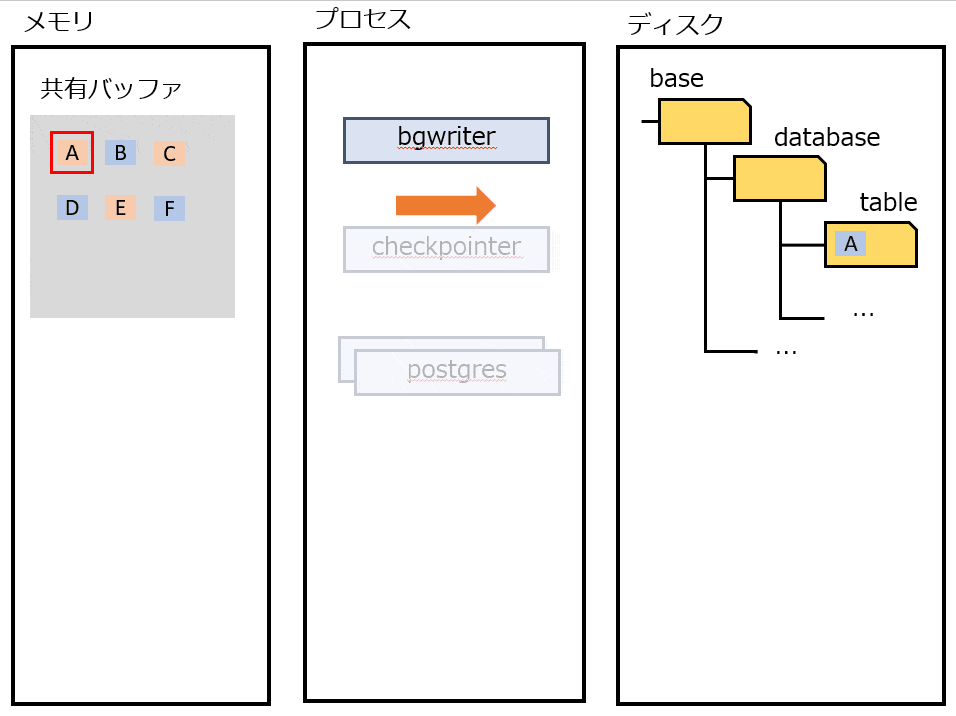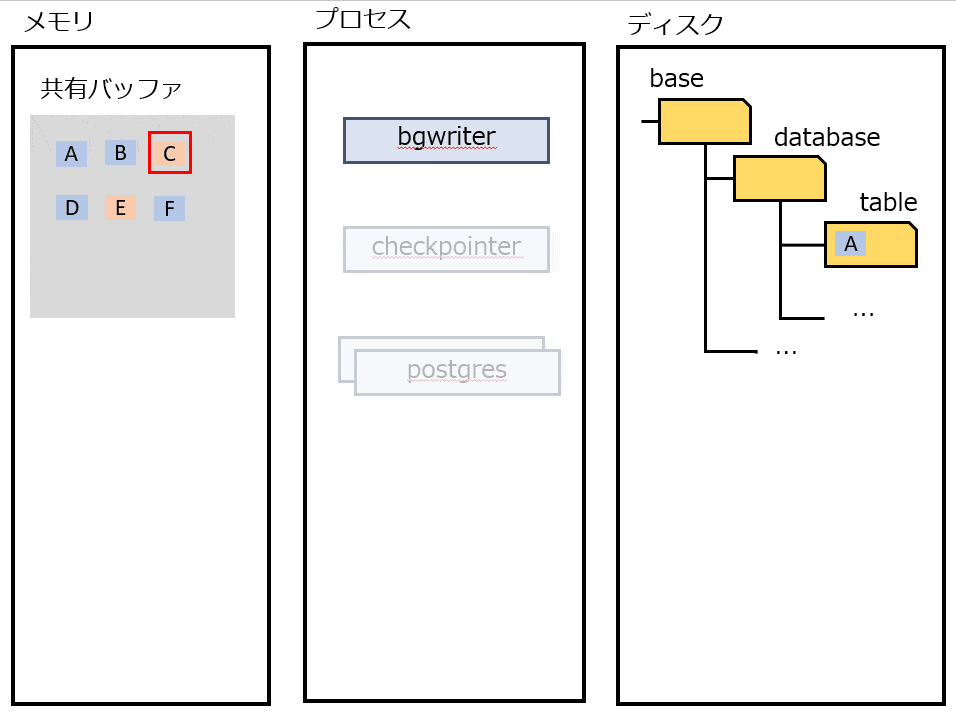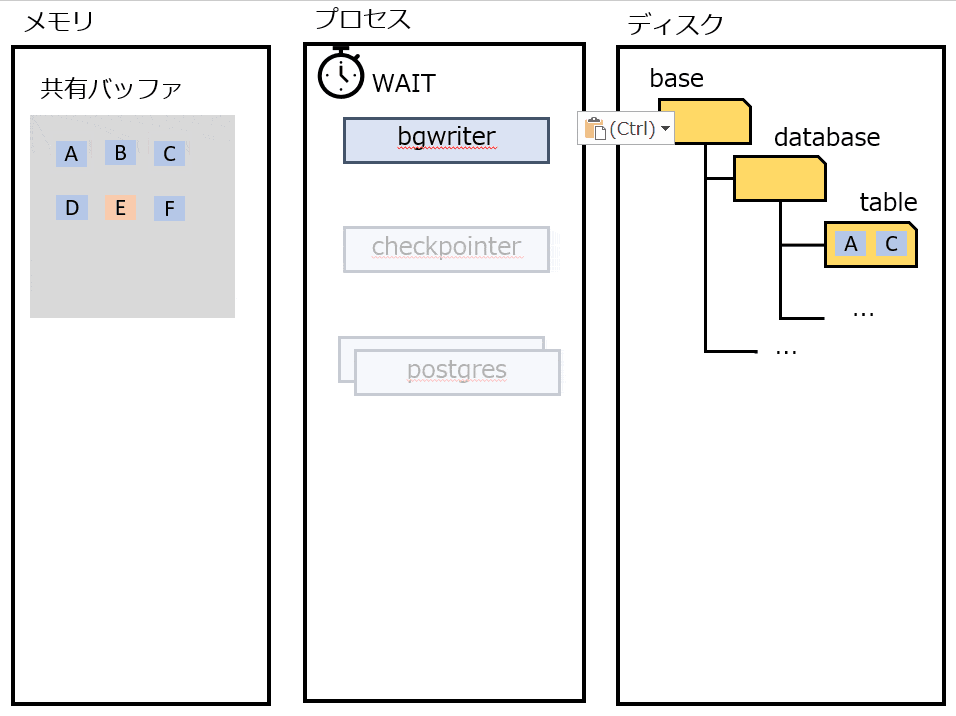
bgwriter
定期的にDirtyな(ディスクと差がある)ページをディスクに書き出す。CHECKPOINT 時の負荷が高まりすぎないように、書き込みをバラけさせる。
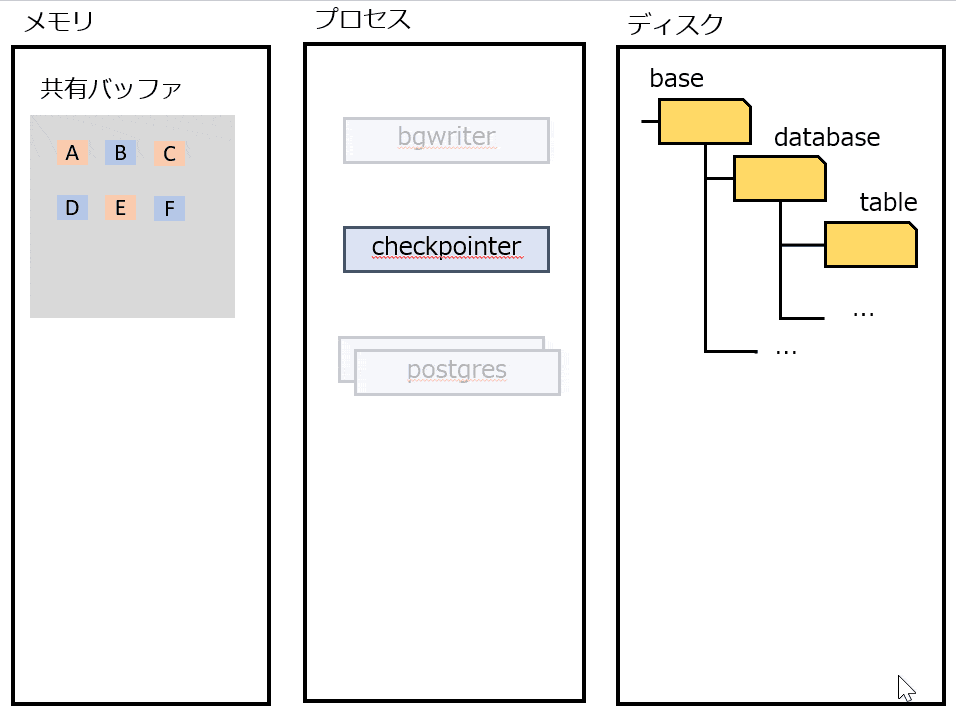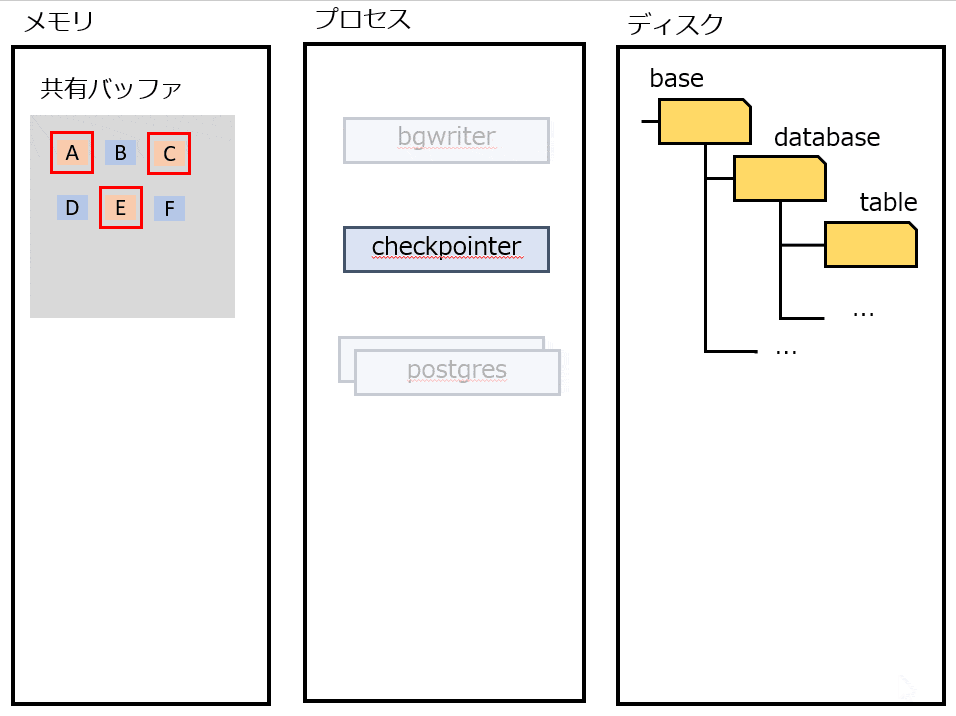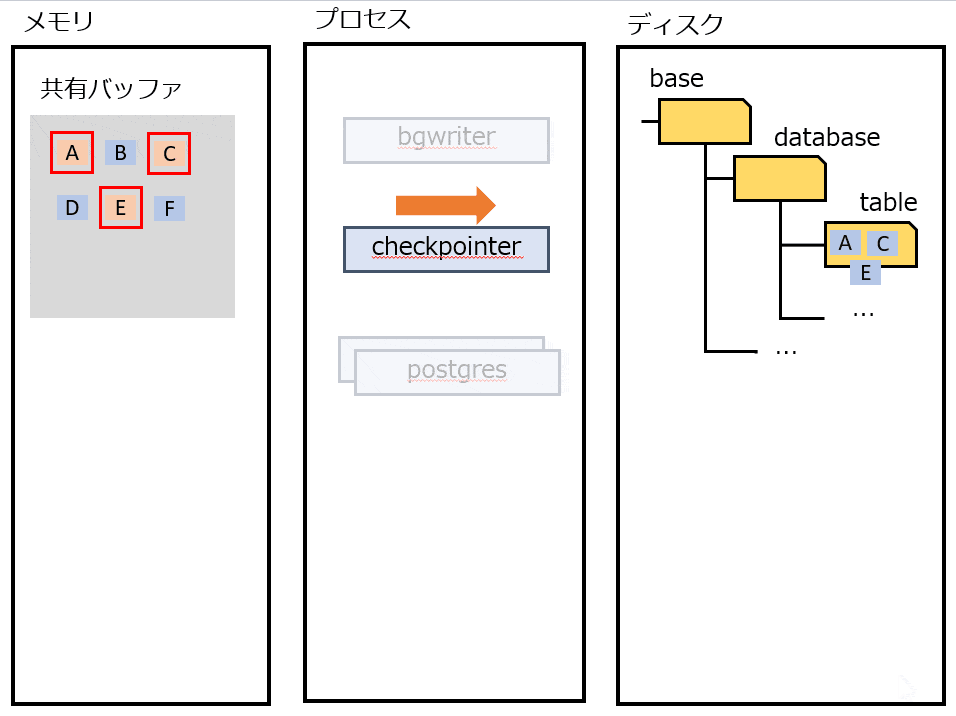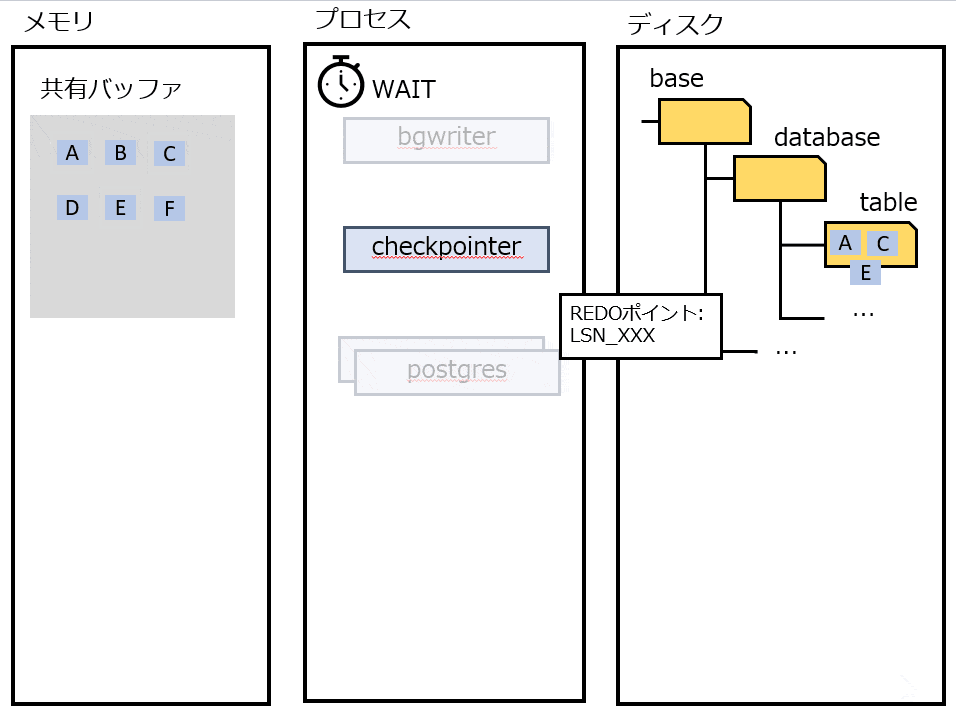
checkpointer
定期的にチェックポイント処理をする。すべてのDirtyなページをディスクに書き出す。この時点の LSN よりも前の操作は、すべてディスクに書き込まれていることが保証される。 チェックポイントをマークするためにpg_controlを更新する。
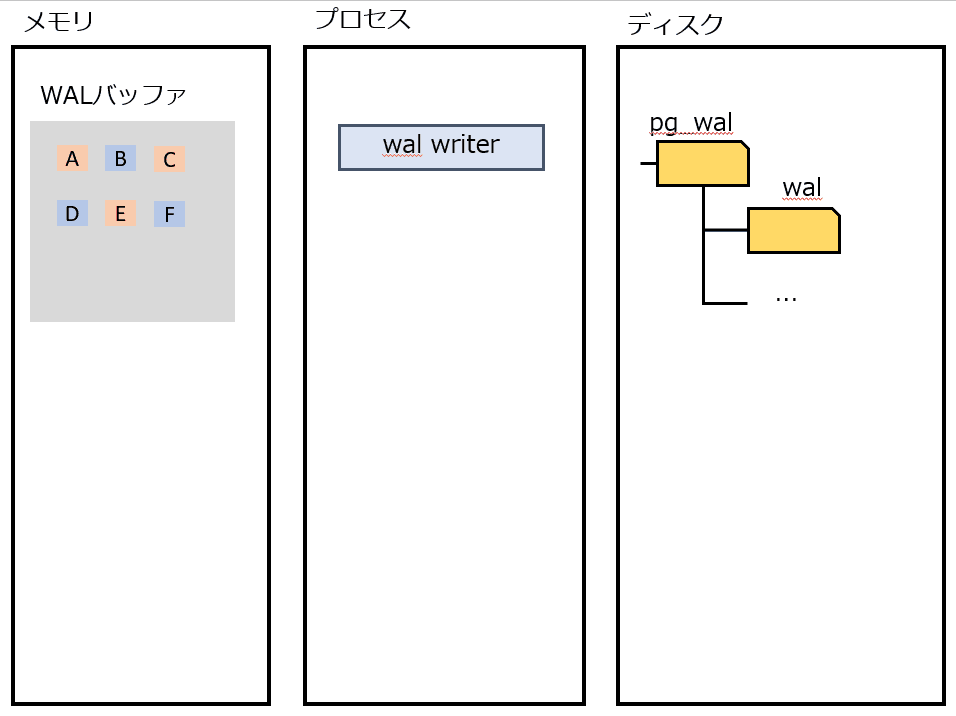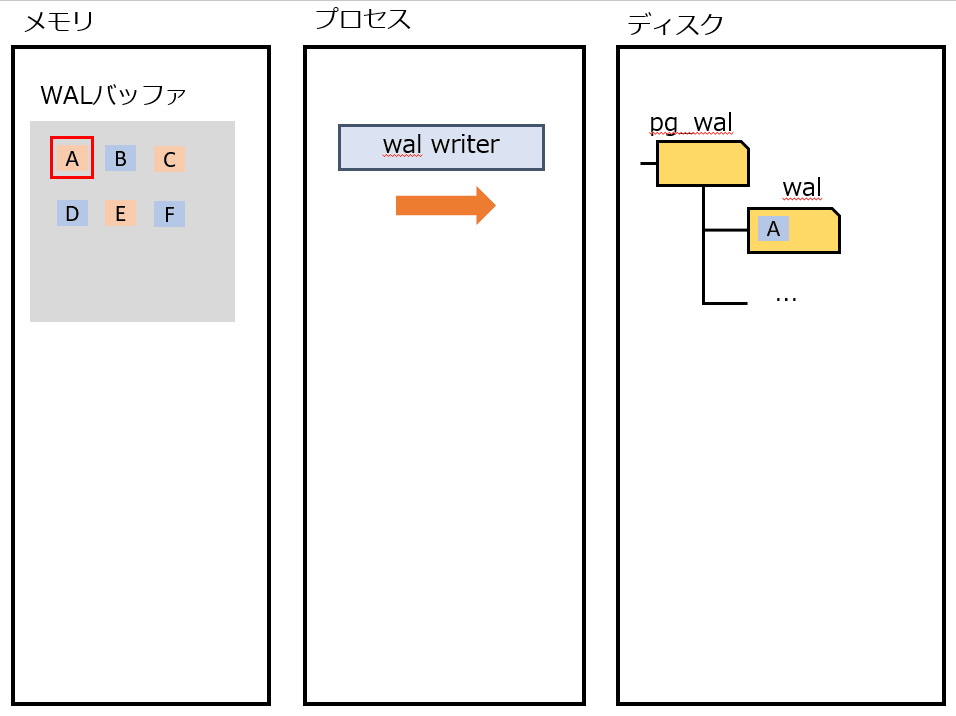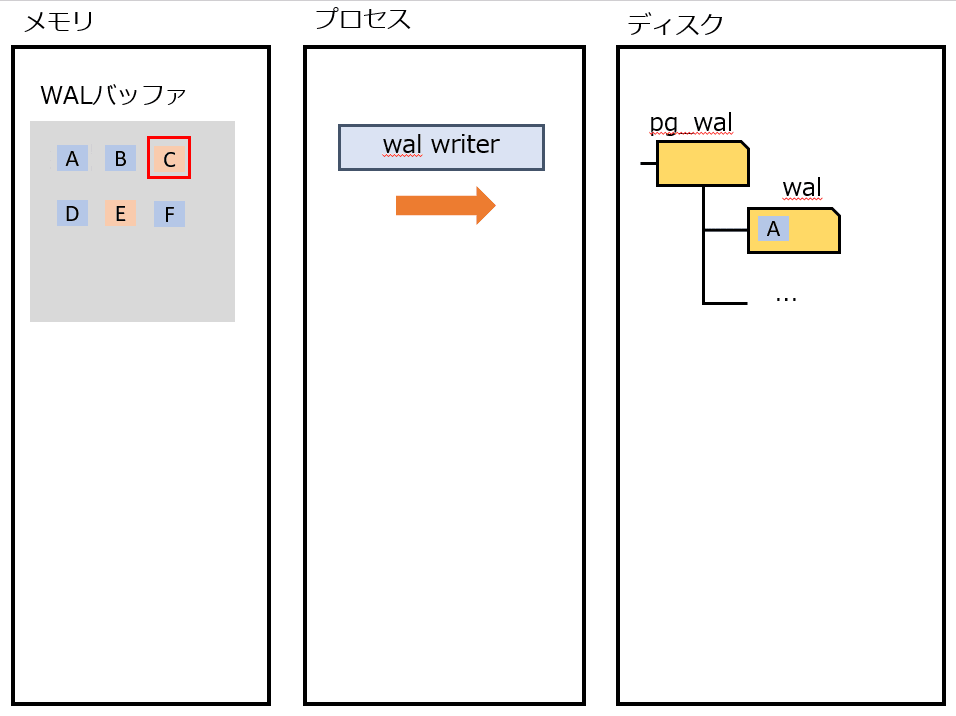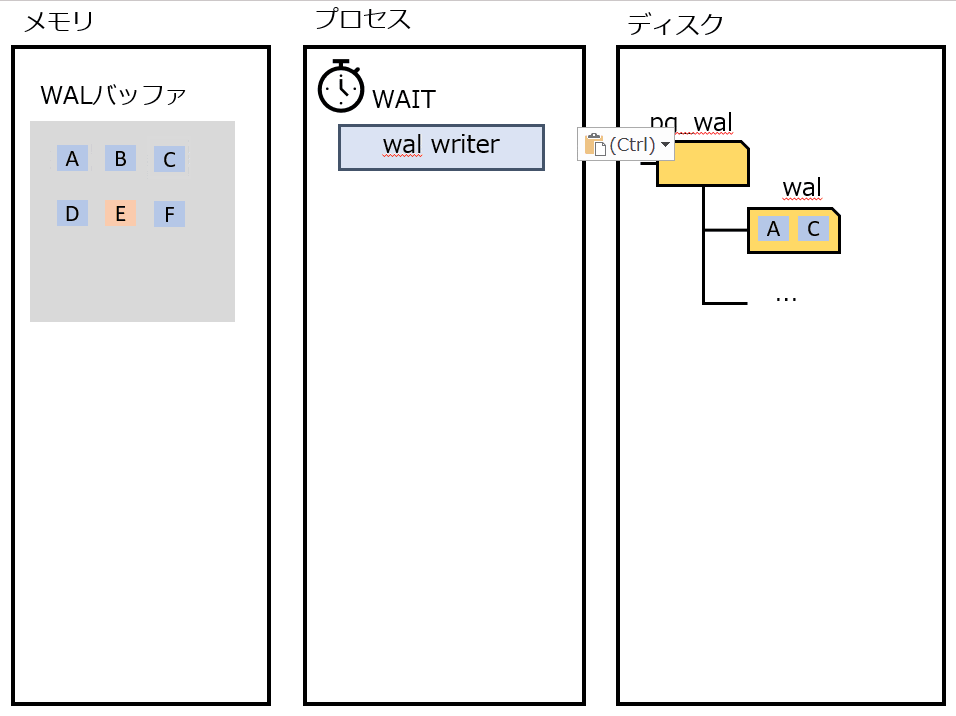
wal writer
定期的にWALをディスクに書き出す。
リカバリ
WAL を読み込み、適用していない処理を繰り返す。
適用していない処理 をどう判別するか?というと、PostgreSQL では、データをページに分割して管理している。各ページを最後に更新した LSN をページ内に記録することで、どの WAL まで適用されたかを判別する。
また、 WAL はこれまでの操作履歴を記録しているので、全ての WAL を適用すればデータベースを復元できる。しかし、データベースを運用してから発生した、全ての WAL を適用するのは現実的ではない。
そのため、CHECKPOINT(=この時点までのデータはすべてディスクに書き出されていると保証されている地点)からの WAL を適用する。
WAL の開始地点は、 REDO ポイントとして pg_control ファイルに記録される。 pg_control の内容は、 pg_controldata コマンドで表示することができる。
$ pg_controldata
pg_control version number: 1002
Catalog version number: 201707211
Database system identifier: 6658384582907850564
Database cluster state: in production
pg_control last modified: 2019年02月16日 18時23分05秒
Latest checkpoint location: 0/150FA710
Prior checkpoint location: 0/150FA578
Latest checkpoint's REDO location: 0/150FA6D8
Latest checkpoint's REDO WAL file: 000000010000000000000015
Latest checkpoint's TimeLineID: 1
Latest checkpoint's PrevTimeLineID: 1
Latest checkpoint's full_page_writes: on
...
pg_control ファイルが壊れた場合、復旧できなくなる。
技術的には、WAL に CHECKPOINT 処理も記載されるため、WAL を新しいレコードから古い方向にたどれば REDO ポイントがわかる。しかし、PostgerSQL はその実装がない。その必要性も薄いらしい。
pg_controlが壊れた場合に備え、ログセグメントを逆順に読み(すなわち新しいものから古いものへと)、最終チェックポイントを見つける方法を実際には実装した方が良いと思われます。 まだこれはできていません。 pg_controlはかなり小さなもの(1ディスクページ未満)ですので、一部のみ書き込みされるという問題は起こりません。 またこの書き込みの時点では、pg_control自体の読み込みができないことによるデータベースエラーという報告はありません。 このため、pg_controlは理屈では弱点ですが、実質問題になりません。
参考 30.5. WALの内部
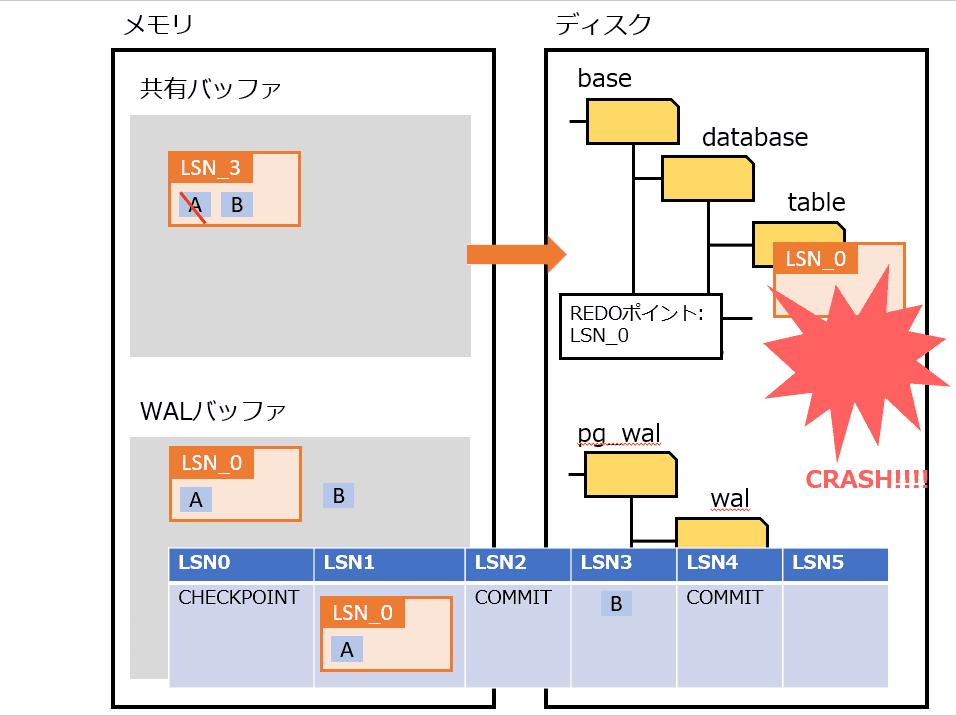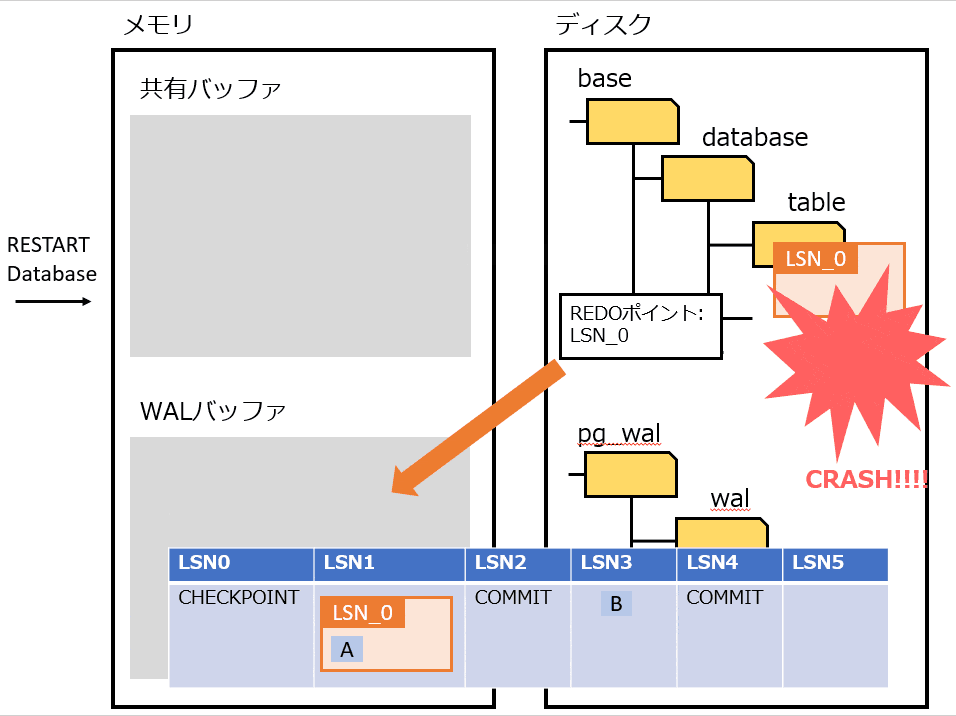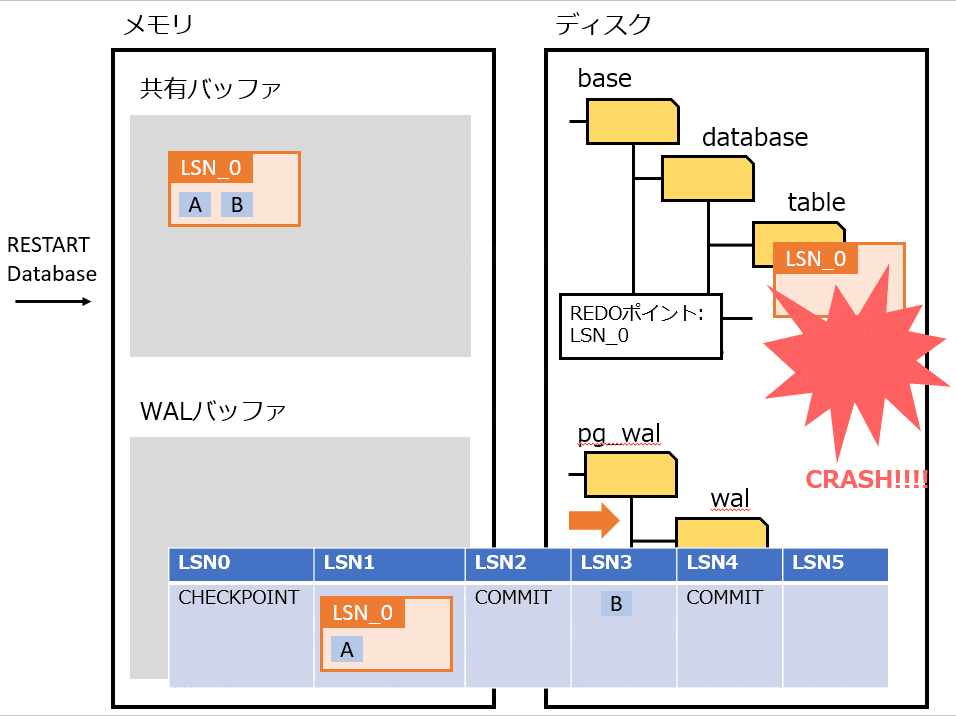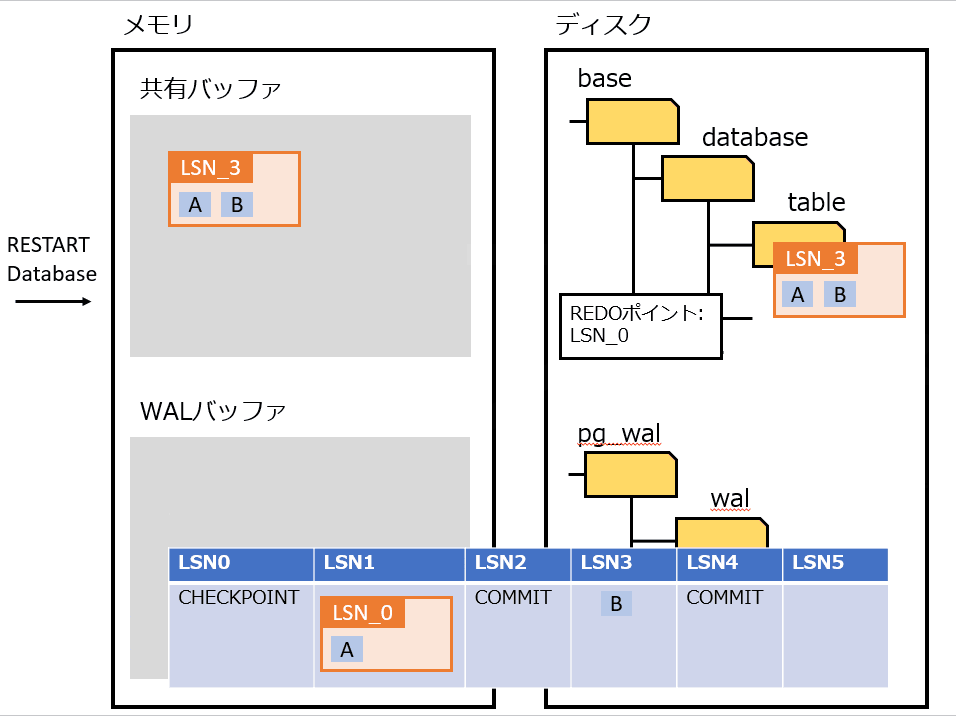
Full Page Writes
物理論理ロギングを実装したもの。
プロセス障害時は、書き込みが途中で中断される可能性がある。その場合、ディスクのページが、新旧のデータが混ざった状態になる可能性がある。そうなってしまうと、WAL から操作を繰り返してもデータは復旧できない。
上記の対策として、チェックポイントの後にそのページが最初に変更された過程で、該当ページを WAL にすべて書き込む。復旧時は WAL に書き込まれたページに置き換えることで、データを復旧する。
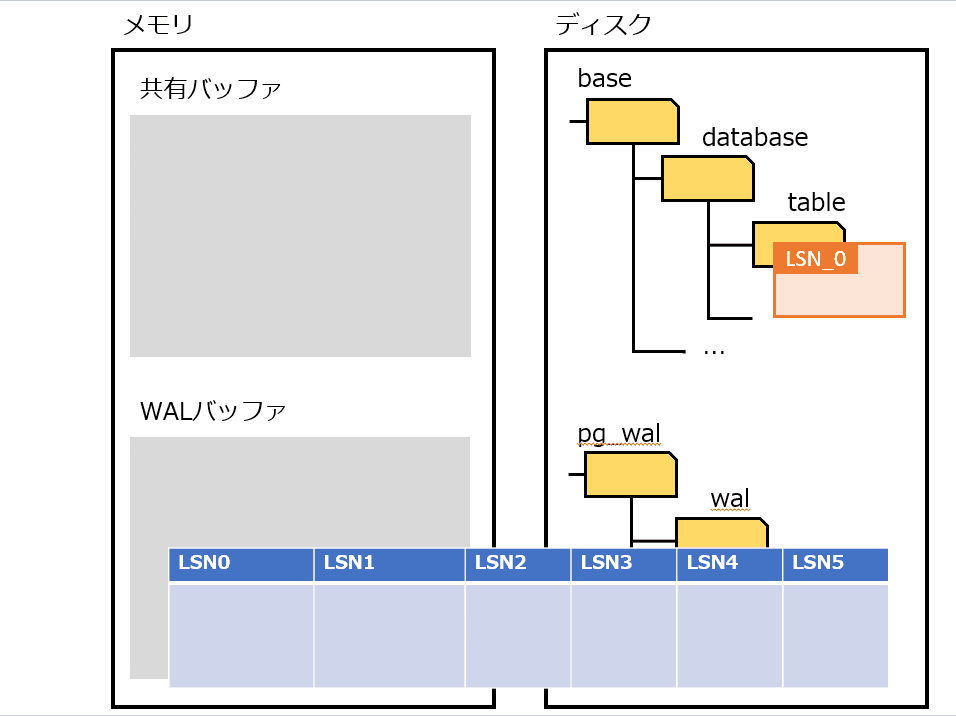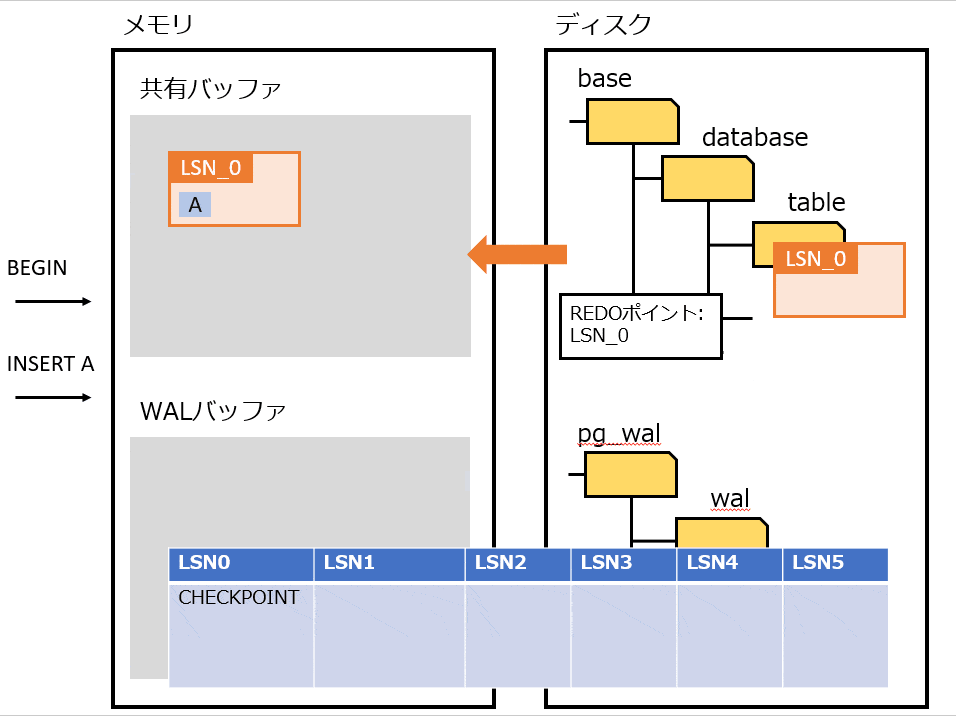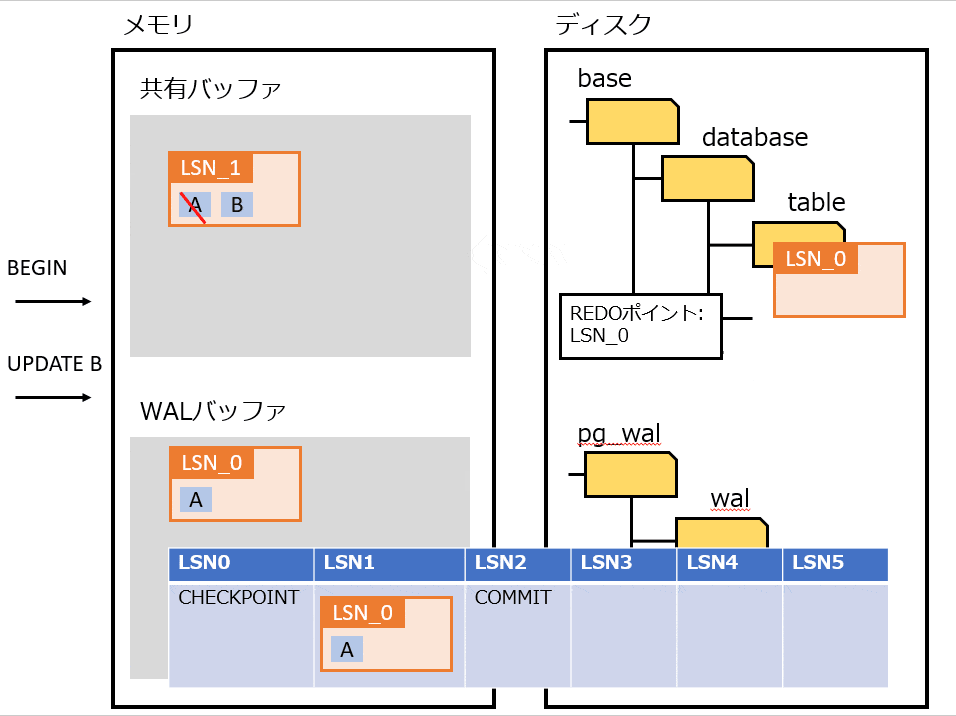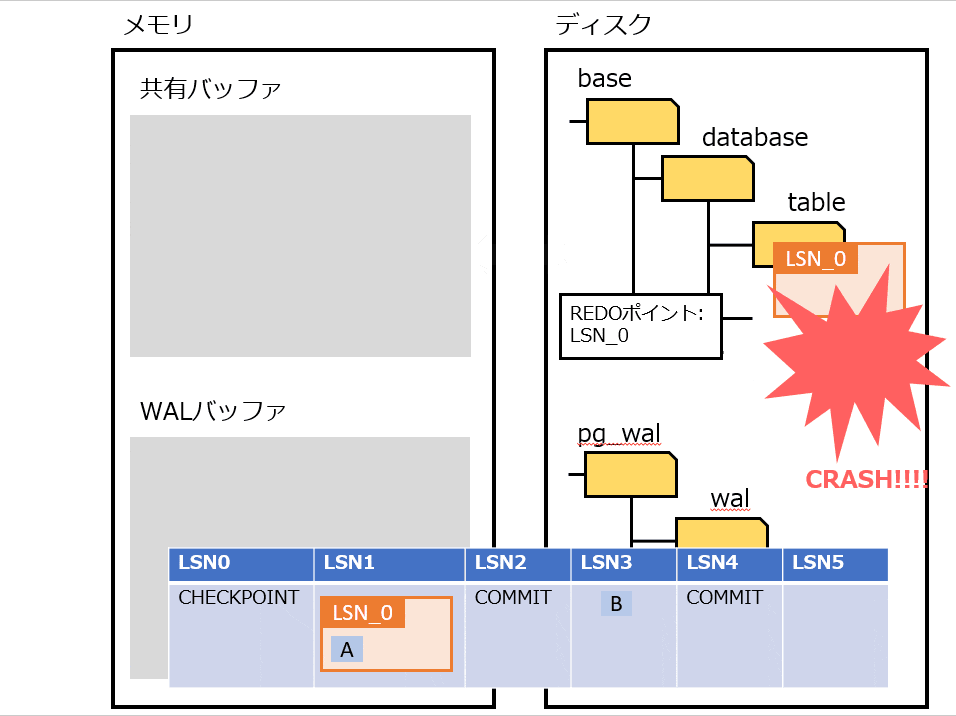
Full Page Writes を利用したときの処理の流れは、以下の通り。
- pg_control から REDOポイント を特定する
- REDOポイント から WAL を最新まで適用する
- チェックポイント後の最初のページは Full Page Writes なので全部置き換える
- それ以降は Page LSN を見て、ページよりも WAL の LSN が大きければ適用する
動作検証
WALの書き込みタイミング
データをディスクに書き込む前に、 WAL に書き込む。 具体的には以下のようなタイミングがある。
WAL の準備
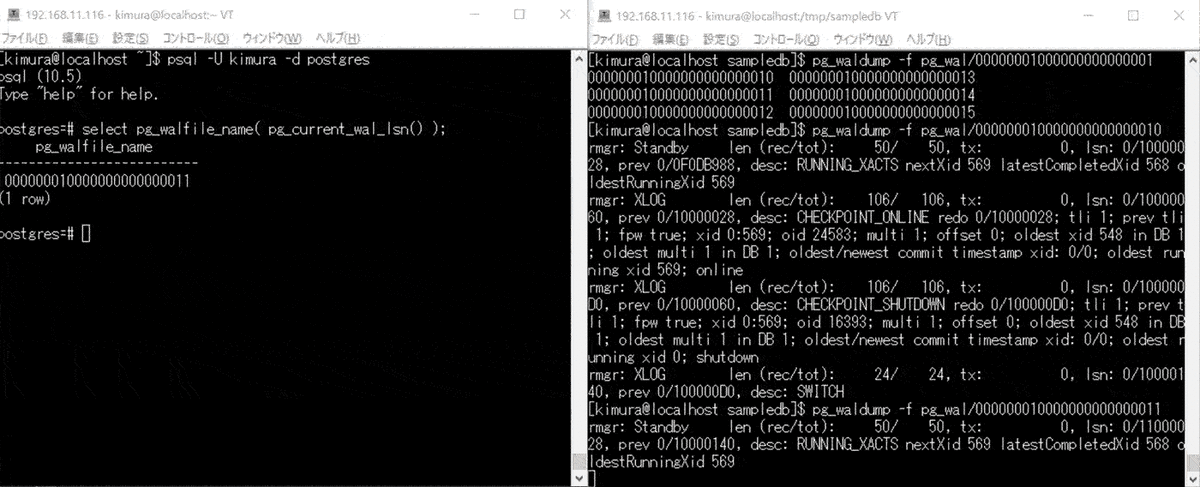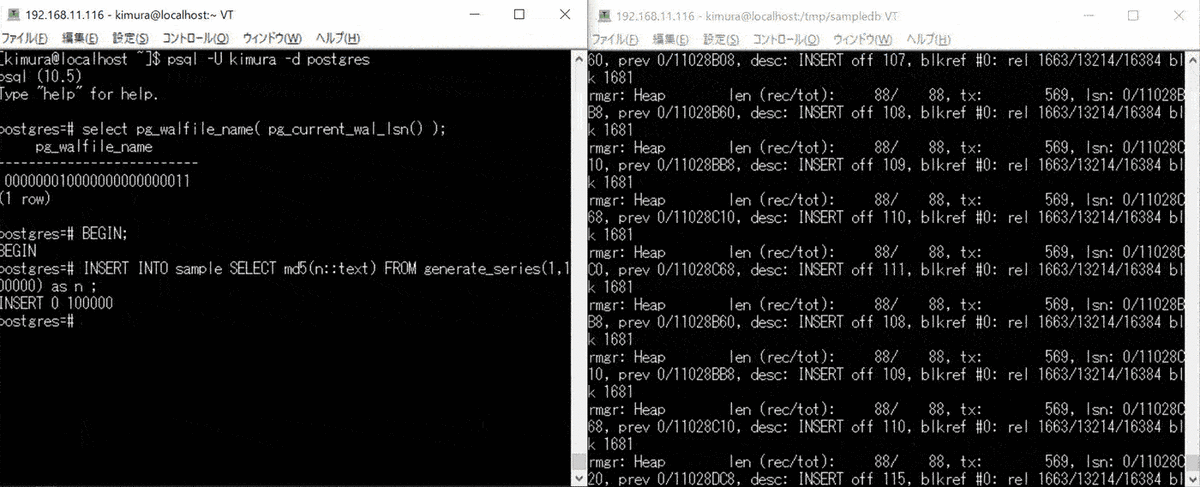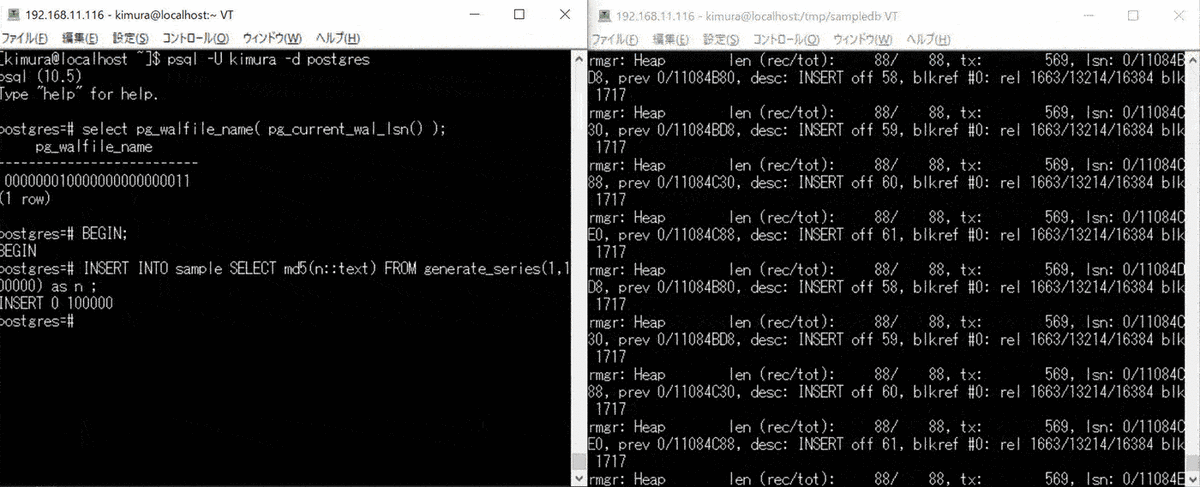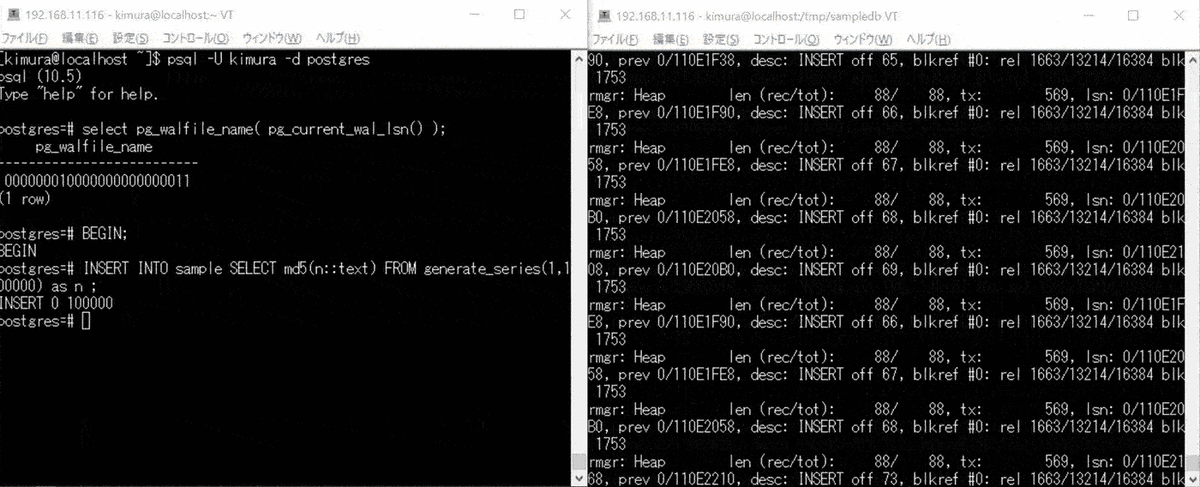
pg_switch_wal()コマンドで WAL を切り替える。pg_walfile_name( pg_current_wal_lsn() )で現在の WAL ファイル名を確認する。
postgres=# select pg_switch_wal();
pg_switch_wal
---------------
0/9004860
(1 row)
postgres=# select pg_walfile_name( pg_current_wal_lsn() );
pg_walfile_name
--------------------------
00000001000000000000000A
(1 row)
表示されたファイルを pg_waldump コマンドでウォッチする。
COMMIT 発行時/ WAL writerの定期実行
# wal_buffers = -1
wal_writer_delay = 200ms
- BEGIN する
- 複数回データを INSERT する
- COMMIT する
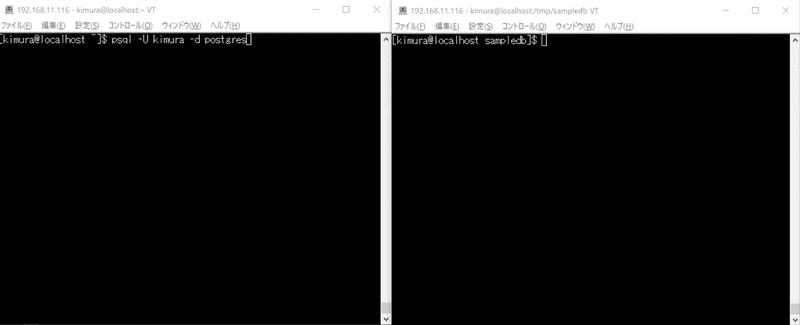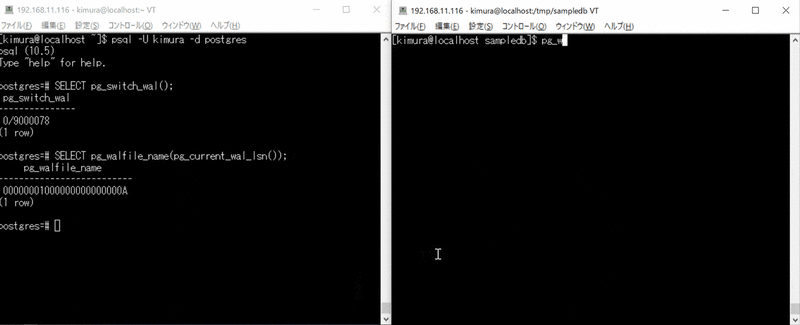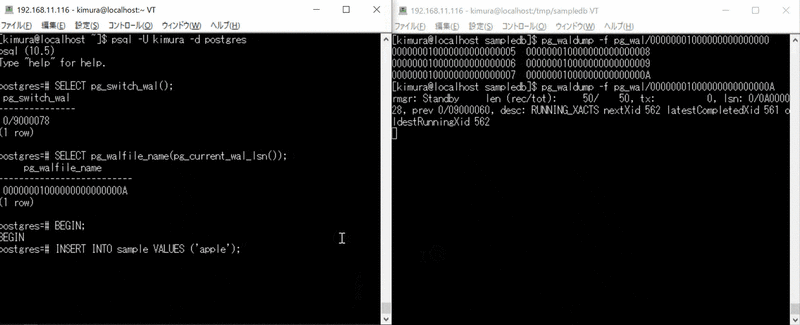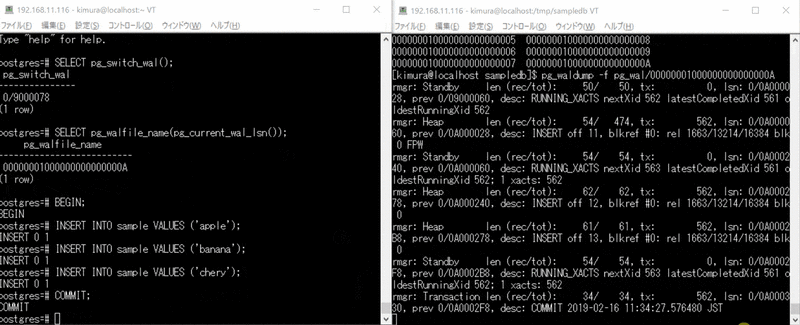
- のとき、wal writer が定期実行している。
- のとき、COMMIT 発行時に書き込みしている。
WALバッファあふれ
wal_writer が動作しないように、wal_writer_delay を多めに設定する。
shared_buffers = 128MB
# wal_buffers はデフォルトでは共有バッファの 1/32(=4MB)
# wal_buffers = -1
wal_writer_delay= 10000ms
- BEGIN する
- 大量データを INSERT する
2 のとき、WAL バッファあふれで書き込みが起きている。
CHECKPOINT, VACUUM実行時
- BEGIN する
- INSERT する
- 別ターミナルで CHECKPOINT を実行する
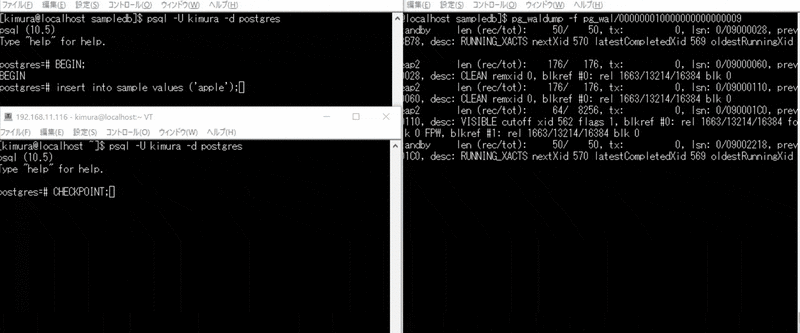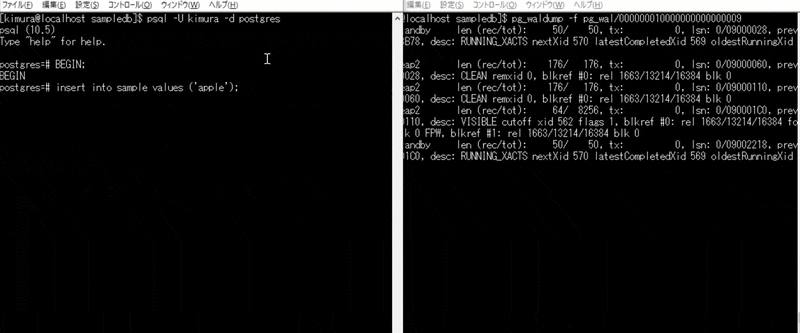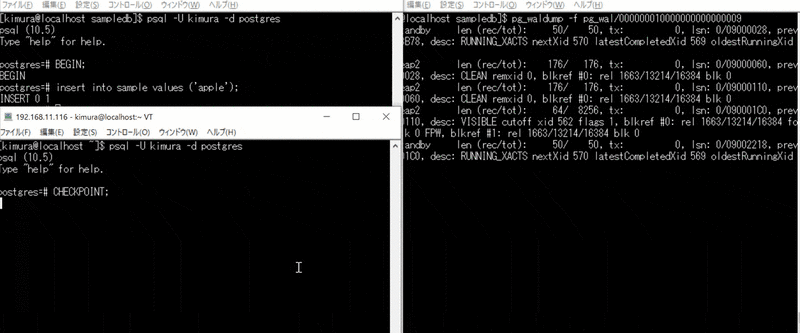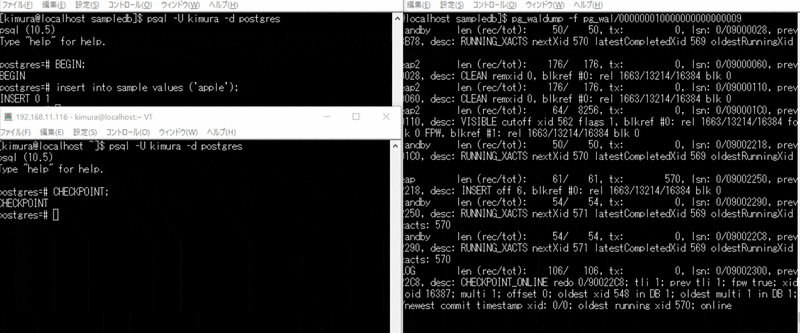
3 のとき、CHECKPOINT で書き込みが起きている。
Dirtyページのディスク書き込みタイミング
テーブルのファイル位置を確認する
SELECT pg_relation_filepathを実行する
postgres=# CREATE TABLE sample (name varchar(100));
postgres=# SELECT pg_relation_filepath('sample');
pg_relation_filepath
----------------------
base/13214/16408
(1 row)
チェックポイント
CHECKPOINT を実行すると、ディスクに書き込まれる。

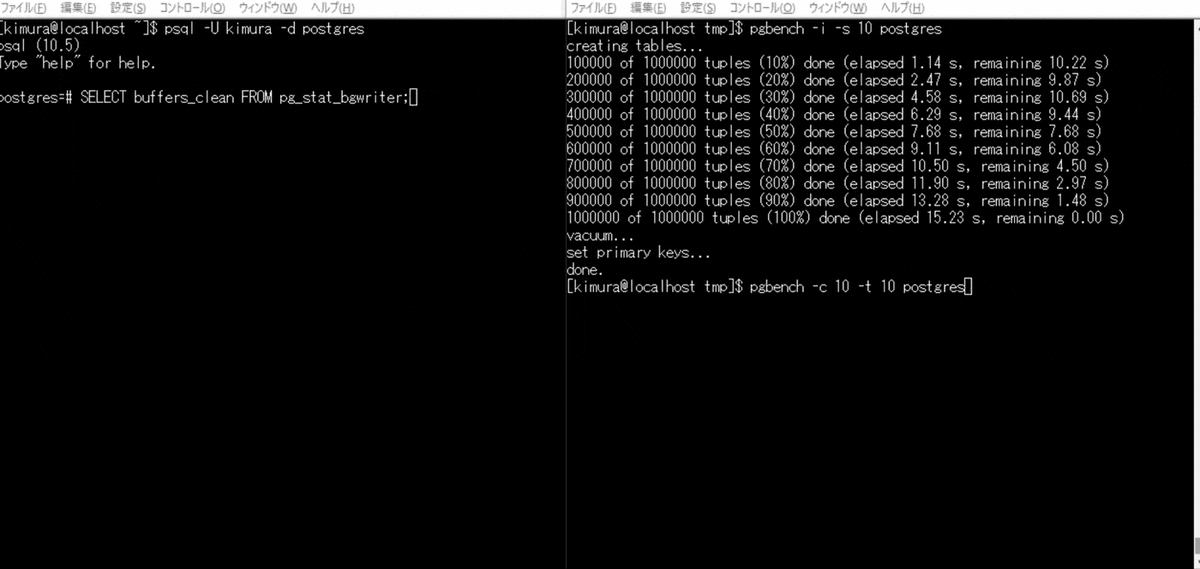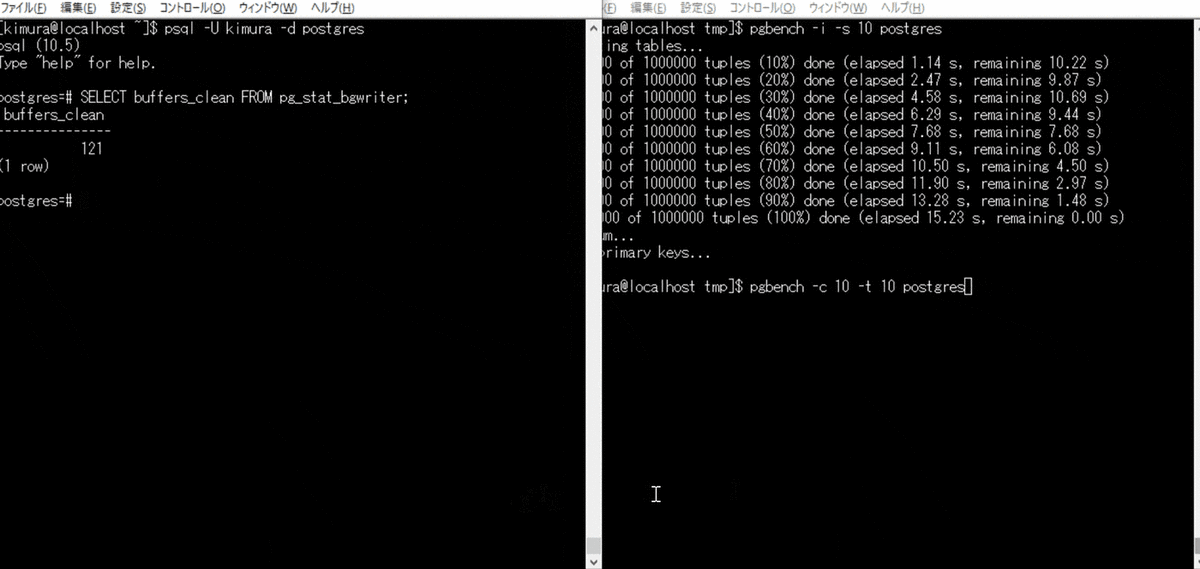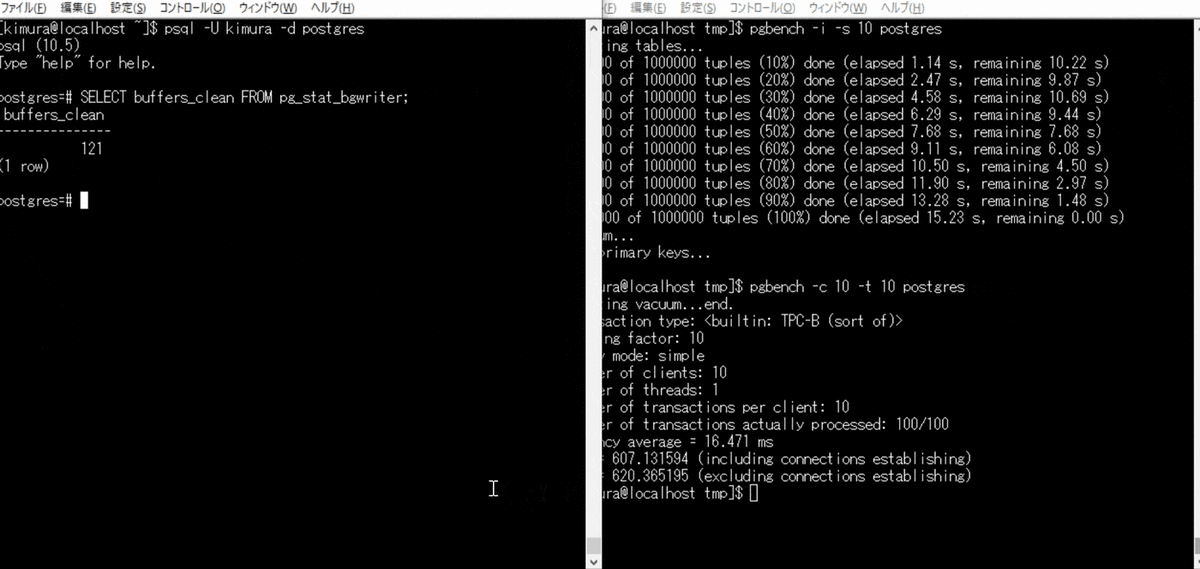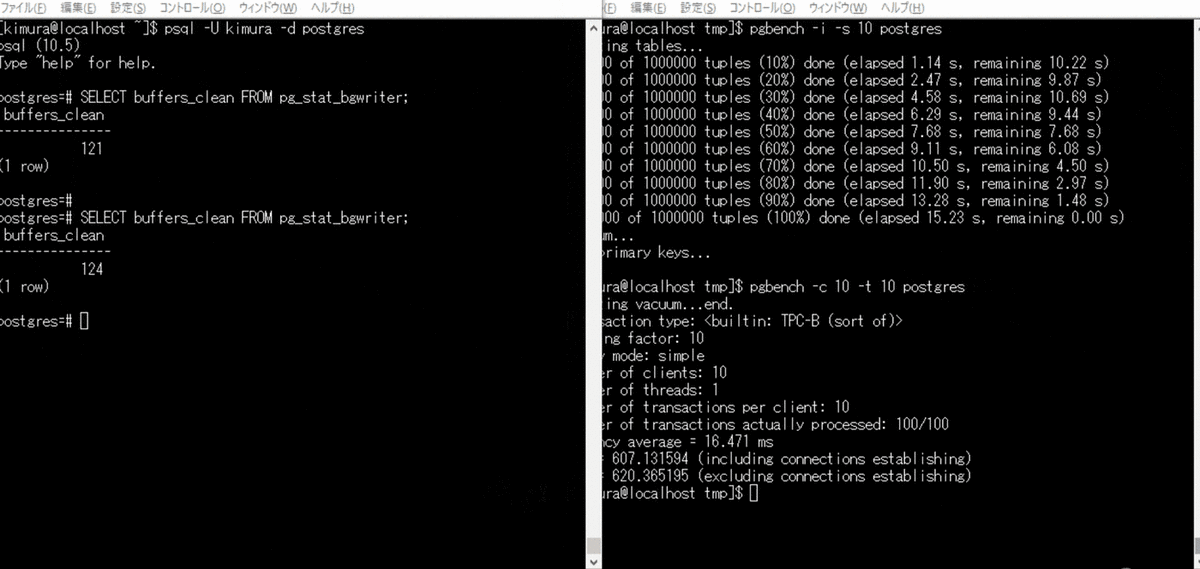
バックグラウンドライタの定期実行
単発でのバックグラウンドライタの実行が難しかったため、 pgbench をかける。 pg_stat_bgwriter ビューの buffers_clean が、バックグラウンドライタにより書き出されたバッファ数のため、これをチェックする。
参考 28.2. 統計情報コレクタ
shared_buffers = 128kB
# bgwriter_delay = 200ms
- pgbench を実行する
- pg_stat_bgwriter を参照する
共有バッファがあふれたとき
共有バッファがあふれるように、小さめに設定する。
shared_buffers = 128kB
- BEGIN する
- 大量にINSERT する
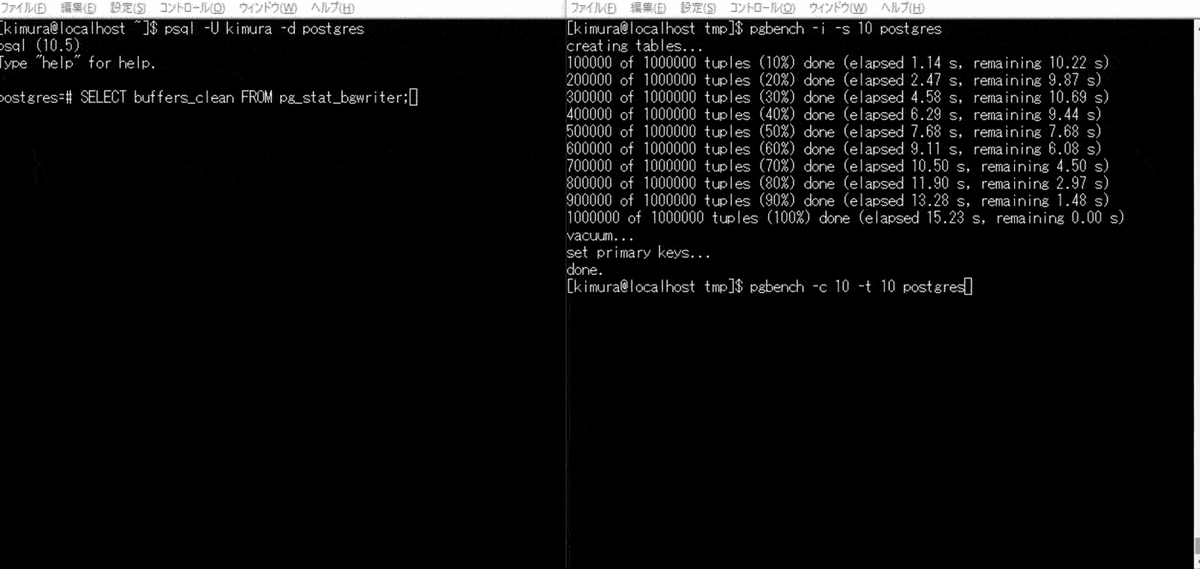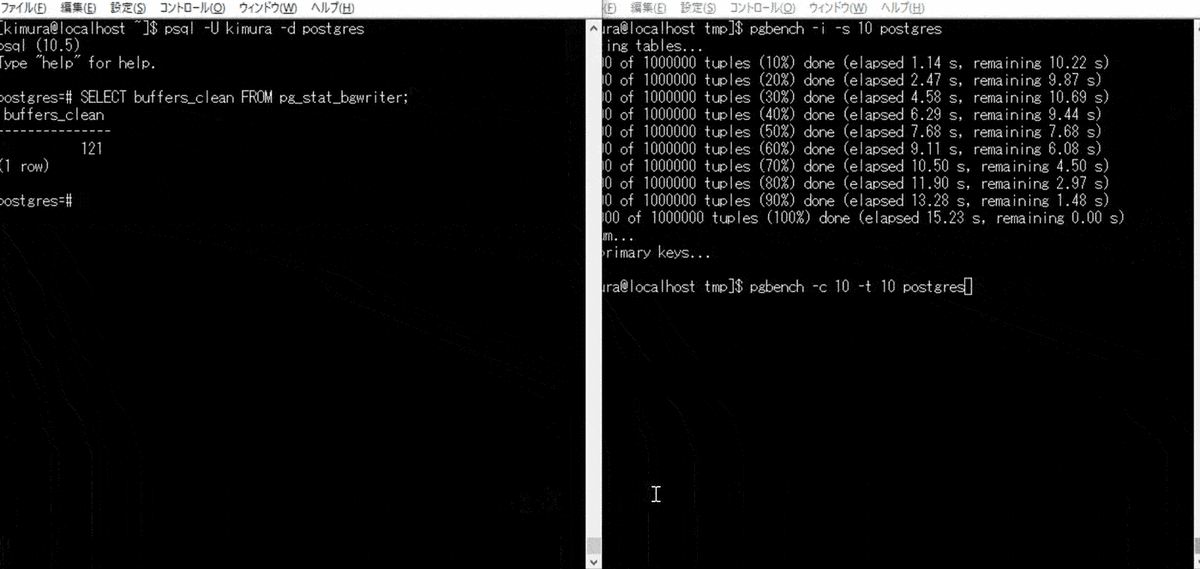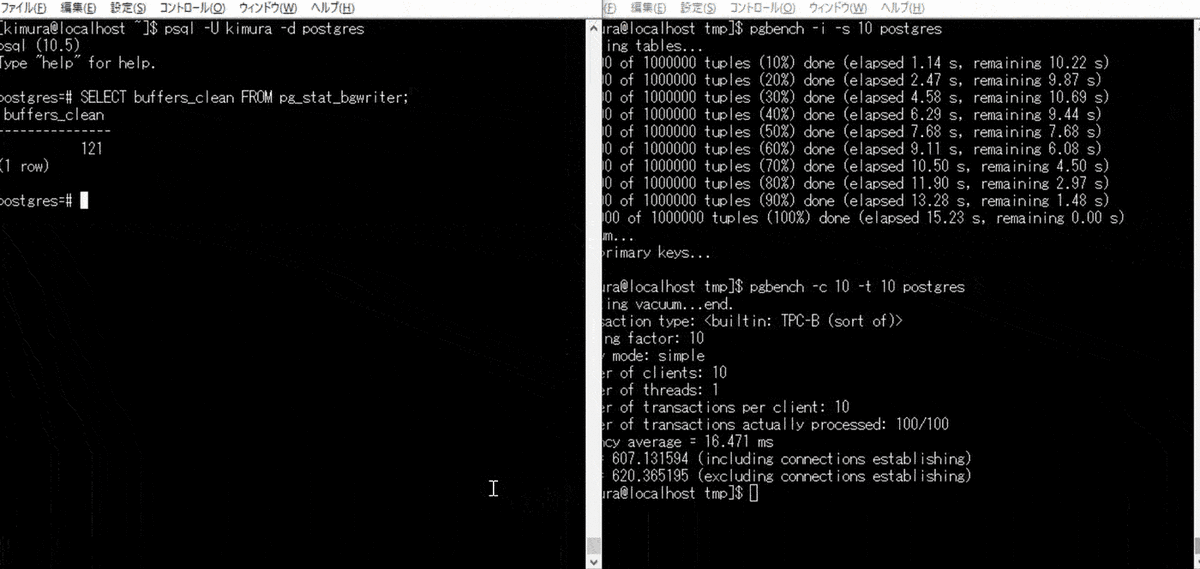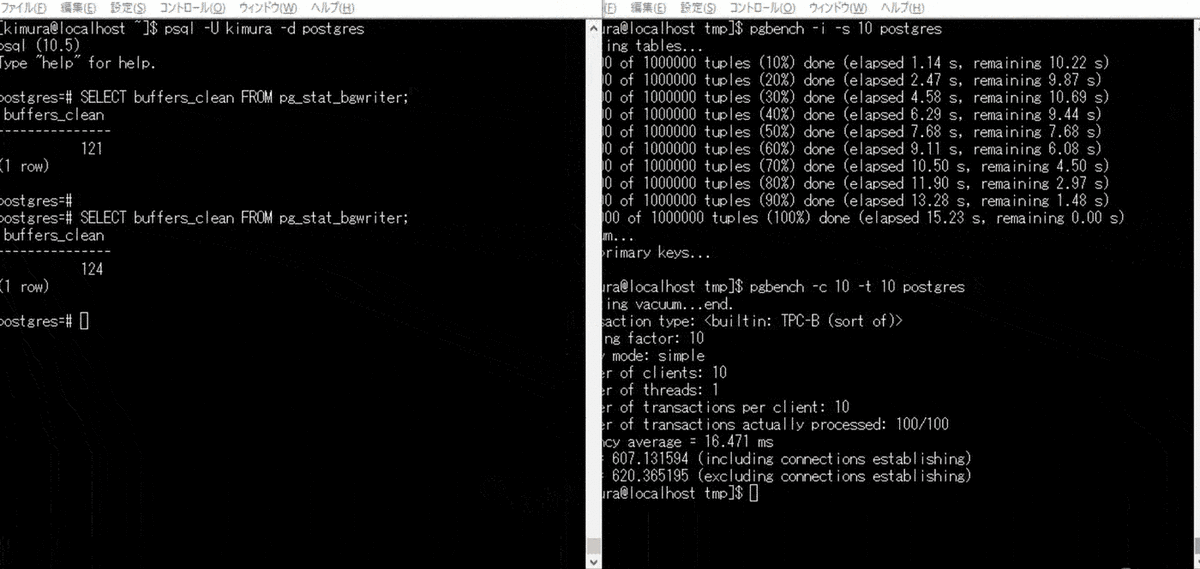
2 のとき、Dirty ページが書き出されている。
リカバリ
pg_control ファイルで、データベースの状態が管理されている。
- 起動時
Database cluster state: in production - 停止時
Database cluster state: shut down
プロセス故障時はこのファイルの状態変更がされずに終わる。 そのため、起動時に in productionの場合に、リカバリが実行される。
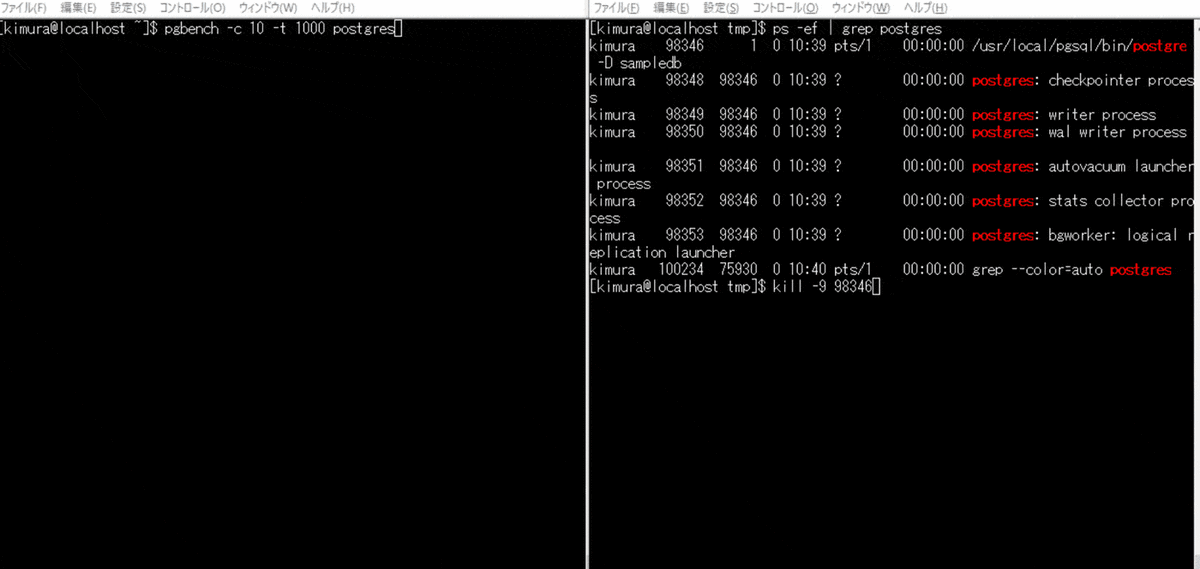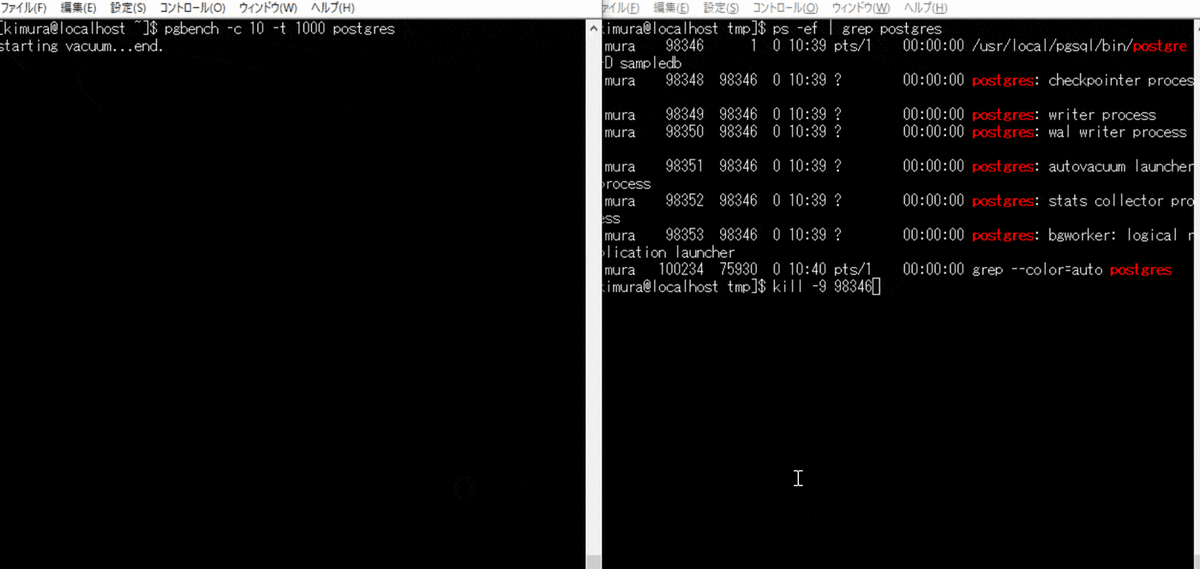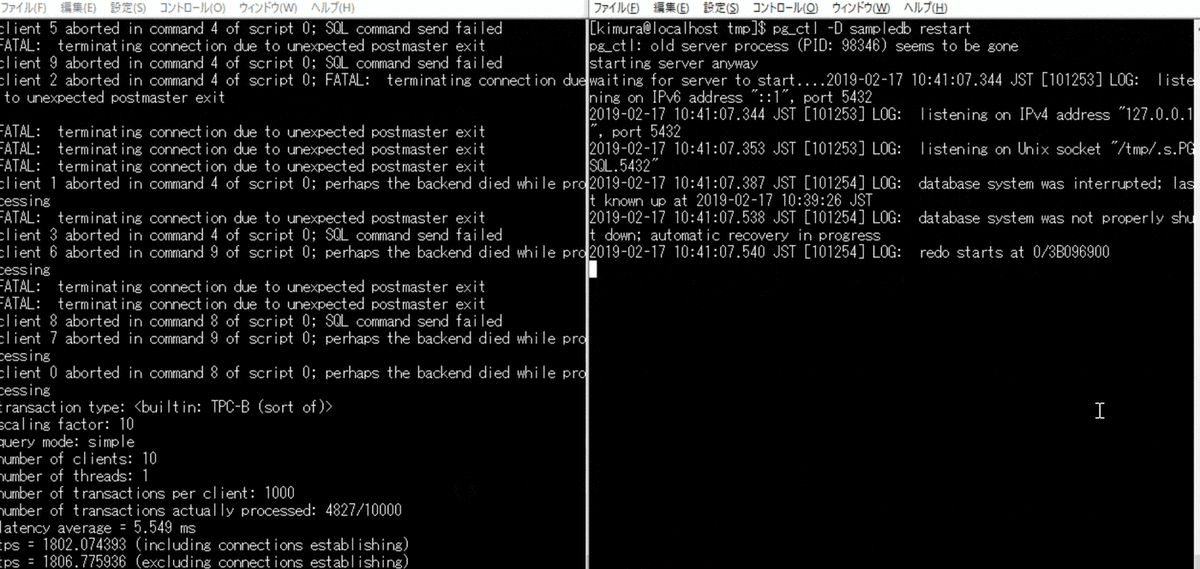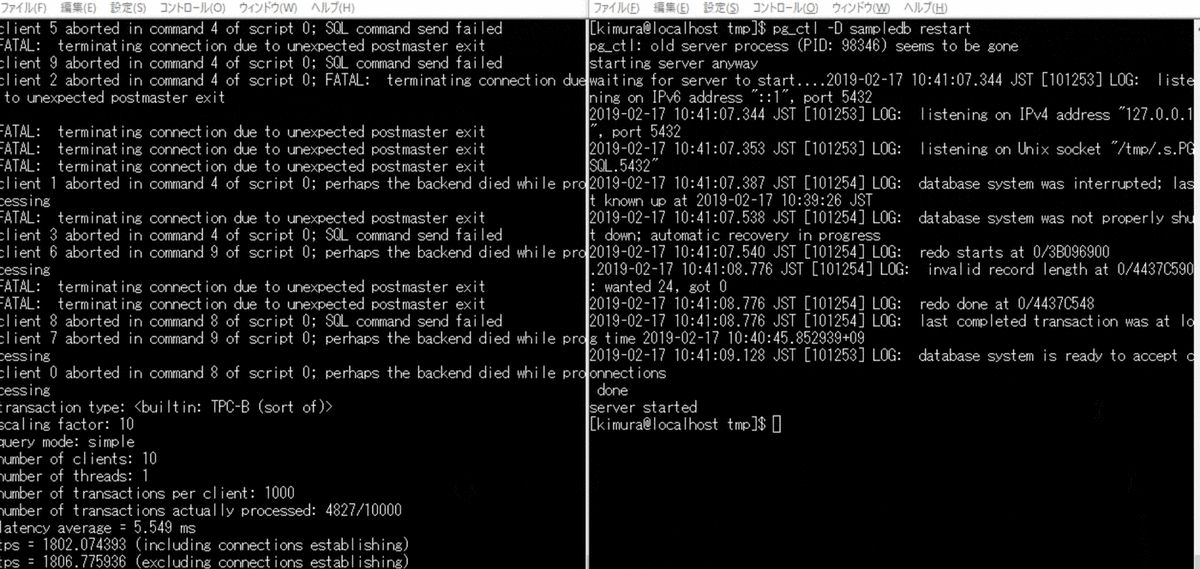
再起動するだけで WAL が適用されていることがわかる。
最後に
データベース、奥が深い。ただの箱じゃない。