検証環境
]# cat /etc/redhat-release
CentOS Linux release 7.7.1908 (Core)
]# uname -a
Linux localhost.localdomain 3.10.0-1062.1.2.el7.x86_64 #1 SMP Mon Sep 30 14:19:46 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
ファイルシステムとは何か?
データを管理/操作するための仕組み。
ファイルとディレクトリで構成されていて、/ を基点とした木構造になっている。
# ls -l /
合計 56
lrwxrwxrwx. 1 root root 7 8月 25 01:17 bin -> usr/bin
dr-xr-xr-x. 6 root root 4096 9月 29 15:51 boot
drwxr-xr-x. 19 root root 3200 9月 29 12:29 dev
drwxr-xr-x. 151 root root 12288 9月 29 12:30 etc
-rw-r--r--. 1 root root 21 9月 29 17:52 hello.txt
drwxr-xr-x. 3 root root 20480 9月 29 17:52 home
lrwxrwxrwx. 1 root root 7 8月 25 01:17 lib -> usr/lib
lrwxrwxrwx. 1 root root 9 8月 25 01:17 lib64 -> usr/lib64
drwxr-xr-x. 2 root root 6 4月 11 2018 media
drwxr-xr-x. 2 root root 6 4月 11 2018 mnt
drwxr-xr-x. 3 root root 16 8月 25 01:21 opt
dr-xr-xr-x. 242 root root 0 9月 29 12:29 proc
dr-xr-x---+ 20 root root 4096 9月 29 21:40 root
drwxr-xr-x. 45 root root 1300 9月 29 19:30 run
lrwxrwxrwx. 1 root root 8 8月 25 01:17 sbin -> usr/sbin
drwxr-xr-x. 2 root root 6 4月 11 2018 srv
dr-xr-xr-x. 13 root root 0 9月 29 12:29 sys
drwxrwxrwt. 32 root root 4096 9月 30 03:34 tmp
drwxr-xr-x. 13 root root 155 8月 25 01:17 usr
drwxr-xr-x. 21 root root 4096 8月 24 16:26 var
各ディストリビューションごとにディレクトリをどう配置するのかは基本的に自由だが、可搬性を高めるために FHS という共通の仕様が定められている。
参考 Wikipedia Filesystem Hierarchy Standard
データはファイルに格納されている。ユーザにファイルという統一したフォーマットを提供することで、データ格納方法の違いをユーザが透過的に扱えるようになっている。
ファイルはopen read write といったシステムコールを通して操作される。このシステムコールを使っていれば、ブロックデバイスへのデータの保存方法の違いや(ext4やxfs)、データがどこから発生しているか(proc はカーネルから情報を取得する)、外部通信が裏で行われるかどうか(sockfs)、などの差をユーザが気にせずに、ファイルを通して統一的にデータを操作することができる。
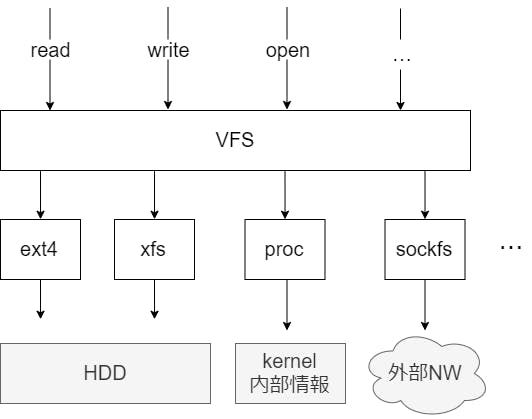
例えば、次のように、 open read write のシステムコールを使って、引数に与えられたファイルの中身を出力するプログラムを実装したとする。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(int argc, char *argv[]) {
char buf[10];
int fd, n;
// 検証コードのため、エラーハンドリングはしない
fd = open(argv[1], O_RDONLY);
while(1) {
n = read(fd, buf, sizeof(buf));
if (n == 0) break;
write(STDOUT_FILENO, buf, n);
}
close(fd);
exit(0);
}
]# gcc -Wall main.c -o mycat
このプログラムは、 xfs のファイルシステムに対しても動作するし、
// xfs ファイルシステムに、ファイルを作成する
]# df -T
ファイルシス タイプ 1K-ブロック 使用 使用可 使用% マウント位置
...
/dev/mapper/centos-root xfs 52403200 20404416 31998784 39% /
...
]# echo "hello xfs filesystem" > /hello.txt
]# ./mycat /hello.txt
hello xfs filesystem
ext4 のファイルシステムに対しても動作する。
// ext4 ファイルシステムに、ファイルを作成する
]# df -T
ファイルシス タイプ 1K-ブロック 使用 使用可 使用% マウント位置
...
/dev/mapper/centos-home ext4 42306664 49196 40085360 1% /home
...
]# echo "hello ext4 filesystem" > /home/hello.txt
]# ./mycat /home/hello.txt
hello ext4 filesystem
また、 proc ファイルシステムに対しても動作する。
]# mount -l | grep proc
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=27,pgrp=1,timeout=0,minproto=5,maxproto=5,direct,pipe_ino=15139)
binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,relatime)
]# ./mycat /proc/meminfo
MemTotal: 7990268 kB
MemFree: 2395808 kB
MemAvailable: 4204892 kB
Buffers: 6080 kB
Cached: 1969472 kB
SwapCached: 0 kB
さらに、なんと、デバイスファイルに対しても動作する。
]# ./mycat /dev/sda2 | head
LABELONE餬酩 LVM2 001mu31U2kbiRP5ZtYc935Jv0HEPNBvVI02霓鞦)荼 LVM2 x[5A%r0N*>霑 J}
centos {
id = "K3vVW6-PQyT-yQDX-pbJG-Y9Pu-mdXf-Mac0J8"
seqno = 1
format = "lvm2"
status = ["RESIZEABLE", "READ", "WRITE"]
flags = []
extent_size = 8192
max_lv = 0
max_pv = 0
...
デバイスファイルとは デバイスドライバとのインタフェースになる仮想的なファイル。ファイルへの I/O 要求を通して、デバイスドライバを実行することができる。
データを一定の塊ごとに扱うものをブロックデバイスという。(例えばHDDやSSD) ブロックデバイスは、 ls -al したときの表示が b から始まる。
]# ls -al /dev/ | grep "^b"
brw-rw----. 1 root disk 253, 0 9月 29 12:29 dm-0
brw-rw----. 1 root disk 253, 1 9月 29 12:29 dm-1
brw-rw----. 1 root disk 253, 2 9月 29 12:29 dm-2
brw-rw----. 1 root disk 2, 0 9月 29 12:29 fd0
brw-rw----. 1 root disk 8, 0 9月 29 12:29 sda
brw-rw----. 1 root disk 8, 1 9月 29 12:29 sda1
brw-rw----. 1 root disk 8, 2 9月 29 12:29 sda2
brw-rw----+ 1 root cdrom 11, 0 9月 29 12:29 sr0
ブロックデバイスへの読み書きはファイルシステムをバイパスするため、前述した例のように、ハードディスクを単にファイルのように読める。(ファイルシステムがディスクを利用している場合、ファイルシステムが書き込んでいる情報がそのまま読める)これは raw/io とも呼ばれる。
データを1文字ごとに扱うものをキャラクタデバイスという。(キーボードやマウスなど) キャラクタデバイスは、 ls -al したときの表示が c から始まる。
]# ls -al /dev/ | grep tty | head
crw-rw-rw-. 1 root tty 5, 2 9月 29 18:16 ptmx
crw-rw-rw-. 1 root tty 5, 0 9月 29 12:29 tty
crw--w----. 1 root tty 4, 0 9月 29 12:29 tty0
crw--w----. 1 root tty 4, 1 9月 29 12:29 tty1
crw--w----. 1 root tty 4, 10 9月 29 12:29 tty10
crw--w----. 1 root tty 4, 11 9月 29 12:29 tty11
例えば、 ssh ログイン時に仮想的に割り当てられるコンソールに対して書き込みをすることで、別ユーザのコンソールに文字列を出力することができる。
参考 tty と pts
いたずらされる人 ]# tty
/dev/pts/1
いたずらする人 ]# echo "キサマ見ているな" > /dev/pts/1
いたずらされる人 ]# キサマ見ているな #<- 勝手に表示される
ファイルアクセスの詳細
ここからは具体例を説明するために、 HDD などのストレージデバイスに話を絞って処理の流れを追いかける。
参考 Documentation/filesystems/vfs.txt
ストレージデバイスの特徴
**ディスクへの読み書きはメモリと比較して非常に遅い。**次のサイトを参考に、実際のアクセス速度の差を見てみよう。
名前 読込速度 読込速度(MB/s) メモリ 10GB/s 10000MB/s SSD(シーケンシャルアクセス) 100MB/s 100MB/s HDD(シーケンシャルアクセス) 100MB/s 100MB/s SSD(ランダムアクセス) 10MB/s 10MB/s HDD(ランダムアクセス) 1MB/s 1MB/s
引用 プログラマが知っておくべき、メモリ/ディスク/ネットワークの速度まとめ
メモリとストレージデバイスではかなりの性能差があることがわかる。そのため、ディスクへの I/O を減らすことが重要になる。これを実現するために、 Linux ではディスクから取得した情報をメモリに余裕がある限りキャッシュするようになっている。メモリに余裕がある限り、キャッシュをじゃぶじゃぶと使い、メモリに余裕がなくなってきたタイミングで回収される。ページ回収の仕組みは今回は扱わないため、詳細を知りたい方は 4.8 スワップアウトとページの破棄 を参考にすること。
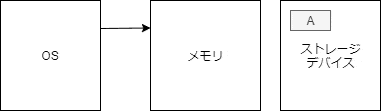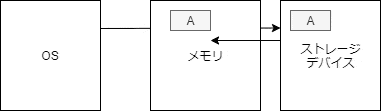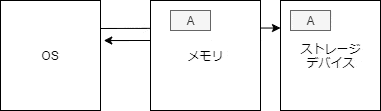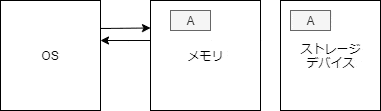
open
まず、構造体の関係性を図示する。
参考 Linux 仮想ファイルシステム・スイッチの徹底調査
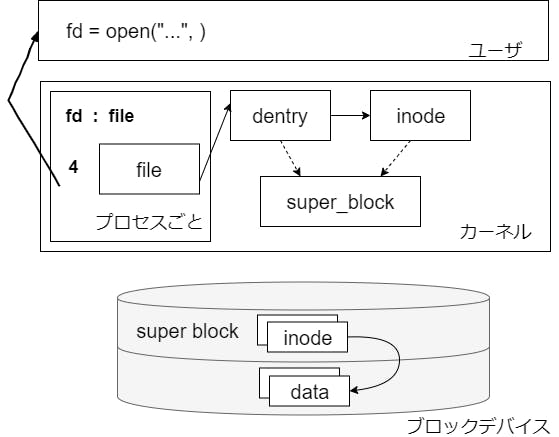
inode
inode は各ファイルやディレクトリの実体を管理する構造体。
参考 linux/include/linux/fs.h
大まかに、次のような情報を持っている。
]# echo "hello world" > /test/hello.txt
// アクセス権、所有者、タイムスタンプ、デバイス、ブロックサイズ を持つ
// ファイル名は inode で持たない。 dentry が持つ。
// ディスク上の位置情報 は inode で持たない。ディスク上の位置情報への変換をファイルシステムごとの get_block_t ハンドラが行う。
]# stat /test/hello.txt
File: `/test/hello.txt'
Size: 12 Blocks: 8 IO Block: 4096 通常ファイル
Device: fd03h/64771d Inode: 110 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-10-05 21:21:41.544219298 +0900
Modify: 2019-10-05 21:26:23.344879923 +0900
Change: 2019-10-05 21:26:23.344879923 +0900
Birth: -
inode は、 inode 番号と呼ばれるパーティション内で一意の番号がふられている。inode 番号は ls コマンドで表示できる。
// ハードリンクの場合、 inode を共有する
// シンボリックリンクの場合、 inode は共有しない(inode へのマッピング情報を持つ)
]# ls -li
合計 8
99 -rw-r--r-- 2 root root 6 10月 5 19:48 sample.txt
99 -rw-r--r-- 2 root root 6 10月 5 19:48 sample_hard_link.txt
100 lrwxrwxrwx 1 root root 10 10月 5 19:49 sample_symbolic_link.txt -> sample.txt
これらの inode は、ディスク上のスーパーブロックに配置されている。この情報は xfs ファイルシステムであれば xfs_db で参照できる。各構造の詳細は Chapter 4. On-disk Inode を参照する。ただし、メモリ上の inode とディスク上の inode は構造が異なる点に注意する。
]# umount /test/
xfs_db /dev/centos/test
xfs_db> inode 110
xfs_db> p
core.magic = 0x494e
core.mode = 0100644
core.version = 3
core.format = 2 (extents)
core.nlinkv2 = 1
core.onlink = 0
core.projid_lo = 0
core.projid_hi = 0
core.uid = 0
core.gid = 0
core.flushiter = 0
core.atime.sec = Sat Oct 5 21:21:41 2019
core.atime.nsec = 544219298
core.mtime.sec = Sat Oct 5 21:21:41 2019
core.mtime.nsec = 544219298
core.ctime.sec = Sat Oct 5 21:21:41 2019
core.ctime.nsec = 544219298
core.size = 12
core.nblocks = 1
...
dentry
ディレクトリの階層構造を管理する構造体。
参考 include/linux/dcache.h
主に、ファイルパスとファイル名と inode を保持する。次のようなイメージ。
以下、「testDir」配下に2つのファイル(article_1、article_2)が存在している状態のdentryのディレクトリ階層管理を見てみましょう(図2)。
testDir testDir/article_1 testDir/article_2
引用 ファイル名を管理するキャッシュdentry (1/2)
これらの情報は、ディスク上にあるディレクトリの inode などから取得する。この情報は xfs ファイルシステムであれば xfs_db で参照できる。
]# mkdir /test/sample_dir
]# touch /test/sample_dir/sample_{1..10}.txt
]# ls -li /test/
合計 0
101 drwxr-xr-x 2 root root 207 10月 5 21:08 sample_dir
]# umount /test/
]# xfs_db /dev/centos/test
// sample_dir の inode を表示する
xfs_db> inode 101
xfs_db> p
core.magic = 0x494e
core.mode = 040755
core.version = 3
core.format = 1 (local)
...
v3.uuid = e48fcf95-cbc3-41cd-8c9d-152aea1ad383
u3.sfdir3.hdr.count = 10
u3.sfdir3.hdr.i8count = 0
u3.sfdir3.hdr.parent.i4 = 96
// ディレクトリに含まれるファイルパスの一覧が取得できる。
u3.sfdir3.list[0].namelen = 12
u3.sfdir3.list[0].offset = 0x60
u3.sfdir3.list[0].name = "sample_1.txt"
u3.sfdir3.list[0].inumber.i4 = 99
u3.sfdir3.list[0].filetype = 1
u3.sfdir3.list[1].namelen = 12
u3.sfdir3.list[1].offset = 0x78
u3.sfdir3.list[1].name = "sample_2.txt"
u3.sfdir3.list[1].inumber.i4 = 100
u3.sfdir3.list[1].filetype = 1
u3.sfdir3.list[2].namelen = 12
u3.sfdir3.list[2].offset = 0x90
u3.sfdir3.list[2].name = "sample_3.txt"
u3.sfdir3.list[2].inumber.i4 = 102
u3.sfdir3.list[2].filetype = 1
u3.sfdir3.list[3].namelen = 12
u3.sfdir3.list[3].offset = 0xa8
実行結果からもわかるが、ディレクトリが持つのはその直下のファイル一覧だけ。そのため/parent_dir/sub_dir/sample.txt というファイルにアクセスしようと思ったら、まず parent_dir の inode をディスクから検索して dentry を作成し、次に sub_dir の inode を をディスクから検索して dentry を作成し、最後に sample.txt の inode を取得する必要がある。このように、ファイルパスの検索は何度も I/O が発生する重たい処理のため、一度作成した dentry はキャッシュされる。また、存在しないパスへのアクセスも negative dentry としてキャッシュされる。
file
各プロセスのオープンファイルの状態を管理する構造体。(シーク位置などを管理する)
参考 include/linux/fs.h
file はテーブル構造で管理されている。ユーザは open 時に取得した fd 番号を read や write 時に指定して読み書きを行う。
dentry キャッシュと inode キャッシュの効果を測定する
dentry キャッシュや inode キャッシュがどの程度有効なのかを確認する。
// 一度キャッシュを捨ててから全ディレクトリパスにアクセスする
]# echo 3 > /proc/sys/vm/drop_caches
]# time ls -R / > /dev/null
real 0m9.140s
user 0m1.708s
sys 0m2.113s
// キャッシュに乗っていると 1/10 で済む
]# time ls -R / > /dev/null
real 0m0.747s
user 0m0.508s
sys 0m0.237s
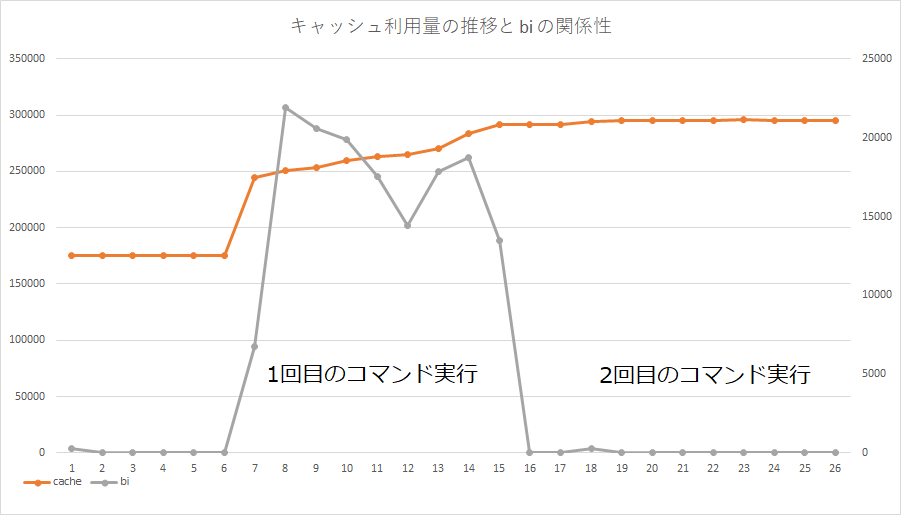
2回目の実行は爆速で終了していることがわかる。このときのリソース情報を vmstat で取得しグラフ化すると、次のようになる。図からも、うまくキャッシュを利用して I/O を削減していることがわかる。
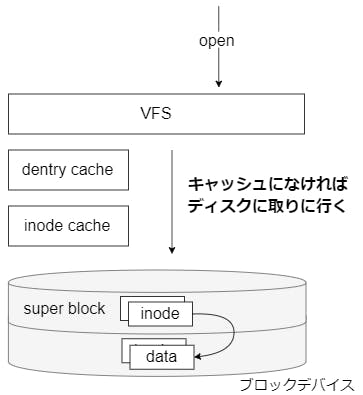
read
read の全体像は次の図のとおり。(open で割愛したディスク I/O の流れも記載している)
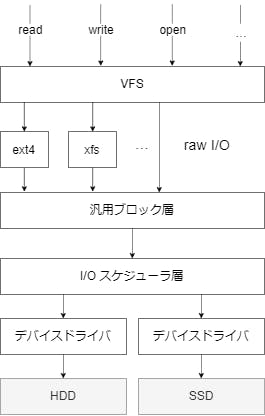
各層で何をやっているかをざっくりとまとめる。
VFS(ファイルシステム)
- open で取得した inode 等をもとに bio 構造体を作成する(bio は I/O を行う実際のセクタ番号や I/O サイズを管理する構造体)
- 変換には、ファイルシステムごとに用意されている get_block_t 型のハンドラを利用する。
- bio を汎用ブロック層に渡す。
汎用ブロック層
- bio をもとに I/O のリクエストを発行する。
- bio をマージして I/O リクエストの数を減らす。
I/O スケジューラ
- I/O リクエストを優先度に基づいて入れ替える。
デバイスドライバ
- 実際にディスクへの読み書きをする
ページキャッシュとバッファキャッシュ
ほとんどのファイルシステムでは、ディスクから読み込んだデータをキャッシュする。データへのアクセス方式によって、ページキャッシュとバッファキャッシュに分けられる。
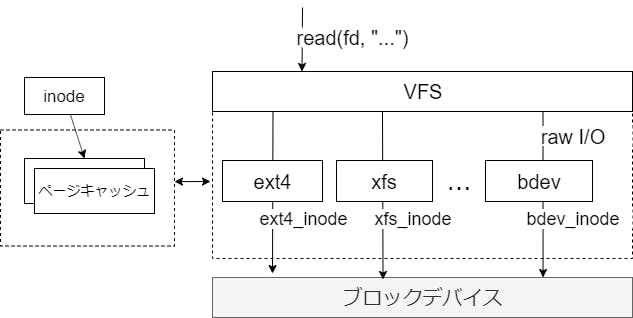
ページキャッシュ
ファイルシステム経由でアクセスしたデータのキャッシュ。
ページキャッシュが利用される様子を実際に確認する。
// 大きなファイルを用意する
]# dd if=/dev/zero of=/test/large.txt count=100 bs=10M
100+0 レコード入力
100+0 レコード出力
1048576000 バイト (1.0 GB) コピーされました、 0.453517 秒、 2.3 GB/秒
]# echo 3 > /proc/sys/vm/drop_caches
// ページキャッシュに乗せる前のメモリ使用量を確認する
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 4368608 0 178284 0 0 30 14 12 40 0 0 99 0 0
]# cat /test/large.txt > /dev/null
// ページキャッシュに乗った後のメモリ使用量を確認する
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 3345876 0 1202524 0 0 38 14 12 40 0 0 99 0 0
キャッシュに乗ったデータへのアクセスは高速であることも確認してみよう。
// 1回目
]# time cat /test/large.txt > /dev/null
real 0m0.471s
user 0m0.006s
sys 0m0.347s
// 2回目
]# time cat /test/large.txt > /dev/null
real 0m0.179s
user 0m0.005s
sys 0m0.174s
バッファキャッシュ
raw I/O 経由でアクセスしたデータをキャッシュする。実装上は、ブロックデバイスに対するページキャッシュになっている。
バッファキャッシュが利用される様子を実際に確認する。
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 4369104 0 178344 0 0 46 22 12 40 0 0 99 0 0
]# dd if=/dev/sda of=/dev/null count=100 bs=10M
100+0 レコード入力
100+0 レコード出力
1048576000 バイト (1.0 GB) コピーされました、 0.999714 秒、 1.0 GB/秒
// バッファキャッシュ(buff)が増加する
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 3340504 1028096 178780 0 0 54 22 12 40 0 0 99 0 0
キャッシュに乗ったデータへのアクセスは高速であることも確認してみよう。
// 1回目
]# time dd if=/dev/sda of=/dev/null count=100 bs=10M
100+0 レコード入力
100+0 レコード出力
1048576000 バイト (1.0 GB) コピーされました、 1.023 秒、 1.0 GB/秒
real 0m1.054s
user 0m0.003s
sys 0m0.481s
// 2回目
]# time dd if=/dev/sda of=/dev/null count=100 bs=10M
100+0 レコード入力
100+0 レコード出力
1048576000 バイト (1.0 GB) コピーされました、 0.190108 秒、 5.5 GB/秒
real 0m0.195s
user 0m0.000s
sys 0m0.195s
また、ブロックデバイスへの直接の read 以外にも、バッファキャッシュが増えるタイミングがある。それは、スーパーブロックへのアクセス時である。ほとんどのファイルシステム(ext4 など)では、inode を取得するときにスーパーブロックに対するアクセス結果をバッファキャッシュに追加する。
// 大量のファイルを用意する
]# mount -l | grep /test
/dev/mapper/centos-test on /test type ext4 (rw,relatime,data=ordered)
]# touch /test/{1..50000}.txt
]# echo 3 > /proc/sys/vm/drop_caches
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 4344936 248 179412 0 0 54 24 13 42 0 0 99 0 0
]# ls -al /test/ > /dev/null
// デバイスファイルへ明示的に read していなくても、バッファキャッシュ(buff)が増加する
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 4268816 14452 241360 0 0 54 24 13 42 0 0 99 0 0
ただし、この動きはファイルシステムに依存する。 xfs などのファイルシステムでは、 inode の管理を自前で実装するためにバッファキャッシュに追加しない。
参考 xfs.org Improving inode Caching
]# mount -l | grep /test
/dev/mapper/centos-test on /test type xfs (rw,relatime,attr2,inode64,noquota)
]# touch /test/{1..50000}.txt
]# echo 3 > /proc/sys/vm/drop_caches
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 4347372 0 178668 0 0 54 22 13 41 0 0 99 0 0
]# ls -al /test/ > /dev/null
// バッファキャッシュ(buff)が増加していない
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 4266984 0 230964 0 0 55 24 13 43 0 0 99 0 0
この挙動に限らず、メモリの使い方はファイルシステムに依存する部分が大きいため、ファイルシステムごとの特徴を押さえる必要があると思う。
direct I/O
ファイルシステム経由でアクセスするが、 I/O の結果をキャッシュに追加しない。たとえば、利用頻度は低いが大きなデータを読み込んだ場合、既存のヒット率の高いキャッシュが追い出されてしまう可能性がある。direct I/O を使うことで、この問題を回避できる。
direct I/O は、 open 時に O_DIRECT フラグを付与することで有効になる。
O_DIRECT (Linux 2.4.10 以降) このファイルに対する I/O のキャッシュの効果を最小化しようとする。このフラグを使うと、一般的に性能が低下する。しかしアプリケーションが独自にキャッシングを行っているような特別な場合には役に立つ。ファイルのI/Oはユーザー空間バッファに対して直接行われる。O_DIRECTフラグ自身はデータを同期で転送しようとはするが、O_SYNCフラグのようにデータと必要なメタデータの転送が保証されるわけではない。同期I/Oを保証するためには、O_DIRECTに加えてO_SYNCを使用しなければならない。下記の「注意」の節の議論も参照。
参考 open(2) man ページ
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 4345392 0 178832 0 0 70 24 13 42 0 0 99 0 0
]# dd if=/dev/sda of=/dev/null count=100 bs=10M iflag=direct
100+0 レコード入力
100+0 レコード出力
1048576000 バイト (1.0 GB) コピーされました、 1.11345 秒、 942 MB/秒
// キャッシュ(buff) が増加していない
]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 4344952 0 179316 0 0 78 24 13 42 0 0 99 0 0
先読み
必要なデータをユーザから要求があるたびに同期的に読み込んでいると、ディスクの I/O 待ちに時間がかかる。そのため、 I/O 要求がシーケンシャルリードだと判断した時点で要求されていない後続のブロックを先読みしておき、キャッシュを充実させる。先読みしたデータは使われるかもしれないし、無駄になるかもしれない。
先読みすることでどの程度効率化されているかを動作確認する。
// 先読みが有効であることを確認する
]# cat /sys/block/sda/queue/read_ahead_kb
4096
]# echo 3 > /proc/sys/vm/drop_caches
]# time dd if=/dev/sda of=/dev/null bs=10M count=100
100+0 レコード入力
100+0 レコード出力
1048576000 バイト (1.0 GB) コピーされました、 1.02561 秒、 1.0 GB/秒
real 0m1.038s
user 0m0.000s
sys 0m0.523s
// 先読みを無効にする
]# echo 0 > /sys/block/sda/queue/read_ahead_kb
]# echo 3 > /proc/sys/vm/drop_caches
]# time dd if=/dev/sda of=/dev/null bs=10M count=100
100+0 レコード入力
100+0 レコード出力
1048576000 バイト (1.0 GB) コピーされました、 44.871 秒、 23.4 MB/秒
real 0m44.884s
user 0m0.000s
sys 0m6.466s
1GB のシーケンシャルリード、かつ 1 プロセスがサーバを占有している、というアプリケーション的にほぼありえないパターンではあるけれど、 40 倍以上の差がでた。
汎用ブロック層
連続した bio を1つの I/O リクエストにマージする。
参考 block/blk-core.c
リクエストのマージでどの程度効率化されているかを確かめる。なお、リクエストのマージは I/O 要求が溜まらないといけないため、検証には HDD を利用する。また、先読みのサイズを減らし、なおかつ並列にアクセスさせる。
]# echo 8 > /sys/block/sdb/queue/read_ahead_kb
]# cat /sys/block/sdb/queue/scheduler
noop [deadline] cfq
]# fio -filename=/hdd/test -directory=/hdd --direct=0 -rw=read -bs=100k -iodepth=64 -size=2g --numjobs=64 -name=file1 --group_reporting -ioengine=libaio
マージの有無は /sys/block/sdb/queue/nomerges で切り替える。
参考 Documentation/block/queue-sysfs.txt
3回測定した結果の平均は次のようになった。マージが有効なほうが若干スループットが高いようだが、測定したスループットの標準偏差が 100 程度だったので、いまいち効果があるかわからなかった。(util はいずれも 100% でディスク中心のワークロード)
| マージの有無 | throughput | ios | merge | ticks | in_queue |
|---|---|---|---|---|---|
| 有効 | 5145 | 121817.3333/0 | 12496/0 | 50129.66667/0 | 50082.33333/0 |
| 無効 | 5118 | 136854.3333/0 | 0/0 | 56798.66667/0 | 56750.33333/0 |
I/O スケジューラ
I/O リクエストを優先度に基づいて入れ替える。当然ながら、 I/O のワークロードや物理構成によって何を優先すべきか(つまり選択すべきスケジューラ)は変わる。
例えば、 SSD だとディスクのシークコストがないため、 noop が性能が出る可能性が高い。
参考 SSDにしたのでI/Oスケジューラを noop に変更してみた
仮想環境ではホスト側で I/O リクエストを効率化するため、ゲスト側は noop にすることが多い。
参考 各OSでのデフォルトI/Oスケジューラの違い
また CPU やストレージの進化によって既存のスケジューラが消えたり、新しいスケジューラが考案されたりもする。例えば、 CPU のマルチコア化やハードディスクの I/O がマルチキュー化しているため、アップストリープのカーネルでは並列性を上げたスケジューラが追加されている。
参考 Linuxカーネル5.0ではCFQ, Deadlineと言ったシングルキュースケジューラが全て削除されてカーネルのデフォルトIOスケジューラ設定も無くなっていました
I/O スケジューラは、このテーマだけで相当深いため、今回はさらっと流す。各スケジューラついての詳細は RHEL7 8.1.1. I/O スケジューラー を参考にする。また、チューニング可能なパラメータについては RHEL 7 パフォーマンスチューニング を参考にする。
現在の I/O スケジューラは次のコマンドで表示できる。
]# cat /sys/block/sda/queue/scheduler
noop [deadline] cfq
I/O スケジューラごとの違いを確認してみる。今回はスケジューラの違いが出やすいように hdd を利用し、noop と deadline を比較した。その結果、 deadline のほうが noop よりも 20% ほどスループットが良い結果となった。
]# echo noop > /sys/block/sdb/queue/scheduler
]# cat /sys/block/sdb/queue/scheduler
[noop] deadline cfq
]# fio -filename=/hdd/test -rw=randwrite -bs=10k -size=1G -numjobs=8 -ioengine=libaio -group_reporting -runtime=20s -name=test
test: (g=0): rw=randwrite, bs=(R) 10.0KiB-10.0KiB, (W) 10.0KiB-10.0KiB, (T) 10.0KiB-10.0KiB, ioengine=libaio, iodepth=1
...
fio-3.7
Starting 8 processes
Jobs: 8 (f=8): [w(8)][100.0%][r=0KiB/s,w=1330KiB/s][r=0,w=133 IOPS][eta 00m:00s]
test: (groupid=0, jobs=8): err= 0: pid=32426: Fri Oct 11 22:20:45 2019
write: IOPS=93, BW=937KiB/s (960kB/s)(18.4MiB/20060msec)
slat (usec): min=16, max=4475.3k, avg=73492.30, stdev=404226.78
clat (usec): min=3, max=162, avg= 6.67, stdev= 5.83
lat (usec): min=21, max=4475.4k, avg=73503.51, stdev=404227.11
clat percentiles (usec):
| 1.00th=[ 4], 5.00th=[ 6], 10.00th=[ 6], 20.00th=[ 7],
| 30.00th=[ 7], 40.00th=[ 7], 50.00th=[ 7], 60.00th=[ 7],
| 70.00th=[ 7], 80.00th=[ 7], 90.00th=[ 7], 95.00th=[ 7],
| 99.00th=[ 42], 99.50th=[ 47], 99.90th=[ 71], 99.95th=[ 163],
| 99.99th=[ 163]
bw ( KiB/s): min= 19, max= 1460, per=43.40%, avg=406.68, stdev=404.33, samples=92
iops : min= 1, max= 146, avg=40.52, stdev=40.44, samples=92
lat (usec) : 4=3.83%, 10=94.63%, 50=1.33%, 100=0.16%, 250=0.05%
cpu : usr=0.05%, sys=0.83%, ctx=4292, majf=0, minf=257
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,1880,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=937KiB/s (960kB/s), 937KiB/s-937KiB/s (960kB/s-960kB/s), io=18.4MiB (19.3MB), run=20060-20060msec
Disk stats (read/write):
sdb: ios=1794/3185, merge=0/0, ticks=20931/780247, in_queue=801177, util=100.00%
]# echo deadline > /sys/block/sdb/queue/scheduler
]# cat /sys/block/sdb/queue/scheduler
noop [deadline] cfq
]# fio -filename=/hdd/test -rw=randwrite -bs=10k -size=1G -numjobs=8 -ioengine=libaio -group_reporting -runtime=20s -name=test
test: (g=0): rw=randwrite, bs=(R) 10.0KiB-10.0KiB, (W) 10.0KiB-10.0KiB, (T) 10.0KiB-10.0KiB, ioengine=libaio, iodepth=1
...
fio-3.7
Starting 8 processes
Jobs: 8 (f=8): [w(8)][100.0%][r=0KiB/s,w=1237KiB/s][r=0,w=123 IOPS][eta 00m:00s]
test: (groupid=0, jobs=8): err= 0: pid=32535: Fri Oct 11 22:22:27 2019
write: IOPS=119, BW=1193KiB/s (1222kB/s)(23.4MiB/20061msec)
slat (usec): min=8, max=4108.3k, avg=66912.99, stdev=346560.95
clat (nsec): min=600, max=139800, avg=4697.79, stdev=3896.23
lat (usec): min=9, max=4108.3k, avg=66921.25, stdev=346560.99
clat percentiles (nsec):
| 1.00th=[ 1304], 5.00th=[ 1496], 10.00th=[ 1608], 20.00th=[ 1800],
| 30.00th=[ 2096], 40.00th=[ 5984], 50.00th=[ 6112], 60.00th=[ 6112],
| 70.00th=[ 6176], 80.00th=[ 6176], 90.00th=[ 6304], 95.00th=[ 6304],
| 99.00th=[ 6688], 99.50th=[ 9920], 99.90th=[ 49408], 99.95th=[ 54016],
| 99.99th=[140288]
bw ( KiB/s): min= 19, max= 1400, per=35.38%, avg=422.12, stdev=405.30, samples=113
iops : min= 1, max= 140, avg=42.08, stdev=40.58, samples=113
lat (nsec) : 750=0.04%
lat (usec) : 2=26.65%, 4=10.40%, 10=62.45%, 20=0.25%, 50=0.13%
lat (usec) : 100=0.04%, 250=0.04%
cpu : usr=0.07%, sys=0.66%, ctx=4713, majf=0, minf=266
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,2394,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=1193KiB/s (1222kB/s), 1193KiB/s-1193KiB/s (1222kB/s-1222kB/s), io=23.4MiB (24.5MB), run=20061-20061msec
Disk stats (read/write):
sdb: ios=2341/567, merge=0/0, ticks=21031/131570, in_queue=152597, util=100.00%
write
バッファリング
ディスクへの読み書きは非常に遅い。そのため、メモリ上のページキャッシュに書き込みを行った時点でユーザに完了を返す。その後カーネルが、更新されたデータを適当なタイミングでディスクに非同期で書き込む。この仕組みによって、複数の write がひとつのディスク I/O にまとめられたり、負荷が低いときに書き込むことができる。この考え方は、データベースのバッファキャッシュと非常に近いと思う。
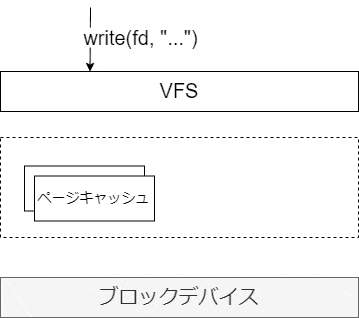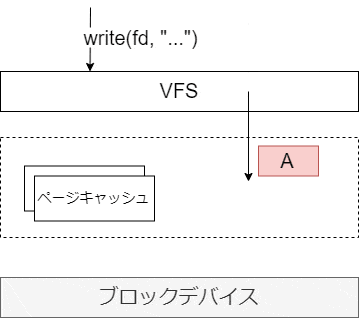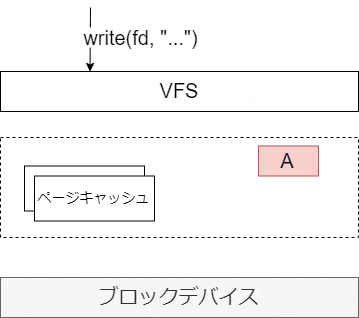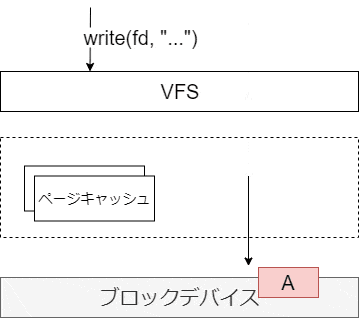
ディスクへの書き込みタイミング
ディスクへの書き込みのタイミングは、次のようなものがある。いずれも、カーネルの flusher スレッドが実行する。
- 決まった時間が経過した
- sync(2) fsync(2) fdatasync(2) が呼ばれた
- ダーティページの割合や合計値のしきい値を超えた
- ページキャッシュに空きが無くなった
詳細なパラメータについては次のサイトを参考にする。
参考 Linuxのdirty page関連パラメータからコードを読む
またページの回収処理中に書き込みされるケースもある。
参考 vm.min_free_kbytes からの wmark_{min|low|high} 算出式
書き込みの同期
書き込んだ内容がバッファリングされるということは、何らかの理由でディスクへの書き込みが失敗することがあるということ。これを防ぐために open 時の O_SYNC オプションやファイルシステムの sync オプション(マウントオプションとして対応されていれば)を使うことで、 write 時のディスクへの同期が保証される。また sync などのシステムコールを利用することで、その時点でのダーティページを書き出すことができる。
たとえば、データベースの WAL 領域への書き込みなどで利用される。
PostgreSQL WALログの仕組みとタイミングを理解したい - SIerだけど技術やりたいブログwww.kimullaa.com
バッファリングする場合としない場合で、どの程度性能差が出るかを確認する。自分の環境では、だいたい 5 倍近くの性能差があった。
// バッファリングする
]# fio -filename=/hdd/test -rw=randwrite -bs=1k -size=100M -numjobs=64 -ioengine=libaio -group_reporting -runtime=60s -name=test
test: (g=0): rw=randwrite, bs=(R) 1024B-1024B, (W) 1024B-1024B, (T) 1024B-1024B, ioengine=libaio, iodepth=1
...
fio-3.7
Starting 64 processes
Jobs: 64 (f=64): [w(64)][100.0%][r=0KiB/s,w=288KiB/s][r=0,w=288 IOPS][eta 00m:00s]
test: (groupid=0, jobs=64): err= 0: pid=42348: Mon Oct 7 06:40:15 2019
write: IOPS=172, BW=173KiB/s (177kB/s)(10.2MiB/60287msec)
...
Run status group 0 (all jobs):
WRITE: bw=173KiB/s (177kB/s), 173KiB/s-173KiB/s (177kB/s-177kB/s), io=10.2MiB (10.7MB), run=60287-60287msec
Disk stats (read/write):
sdb: ios=9192/4100, merge=0/0, ticks=61725/294743, in_queue=356457, util=100.00%
// バッファリングしない
]# fio -filename=/hdd/test -rw=randwrite -bs=1k -size=100M -numjobs=64 -ioengine=libaio -group_reporting -runtime=60s -sync=1 -name=test
test: (g=0): rw=randwrite, bs=(R) 1024B-1024B, (W) 1024B-1024B, (T) 1024B-1024B, ioengine=libaio, iodepth=1
...
fio-3.7
Starting 64 processes
Jobs: 35 (f=35): [w(6),_(1),w(2),_(1),w(3),_(1),w(1),_(1),w(1),_(4),w(5),_(8),w(4),_(4),w(1),_(3),w(6),_(2),w(1),_(1),w(1),_(2),w(2),_(1),w(2)][3.4%][r=0KiB/s,w=28KiB/s][r=0,w=28 IOPS][eta 28m:59s]
test: (groupid=0, jobs=64): err= 0: pid=42606: Mon Oct 7 06:42:53 2019
write: IOPS=33, BW=33.5KiB/s (34.4kB/s)(2081KiB/62032msec)
...
Run status group 0 (all jobs):
WRITE: bw=33.5KiB/s (34.4kB/s), 33.5KiB/s-33.5KiB/s (34.4kB/s-34.4kB/s), io=2081KiB (2131kB), run=62032-62032msec
Disk stats (read/write):
sdb: ios=2008/4159, merge=0/0, ticks=18993/74751, in_queue=93878, util=100.00%
(参考) ファイルの削除
ファイル削除に利用する rm コマンドは、ディスク上からファイルのデータを消すことは保証していない。ファイルシステムごとに詳細の実装は異なるが、ファイルシステム上から該当のファイルを見えないようにしてるだけの事が多い。そのため、消したはずのデータを参照する、ということができる。
実際に確かめてみる。
// 空の xfs ファイルシステムを作成する
]# mkfs.xfs -f /dev/centos/test
meta-data=/dev/centos/test isize=512 agcount=4, agsize=65536 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
// ディレクトリにマウントし、秘密のファイルを作成する
]# mount /dev/centos/test /test/
]# echo "PASSWORD: secret" > /test/password.txt
]# sync
// 秘密のファイルを削除する
]# rm /test/password.txt
]# sync
// デバイスファイル経由でディスクの中身を見ると、削除したファイルの残骸が見える
]# strings /dev/mapper/centos-test
XFSB
...
PASSWORD: secret
d h]
...
`password.txt
...
ということで、ファイルを消したから安全だ、というわけではない。ディスクを廃棄するときは専門業者に頼むか、少なくとも全ブロックを /dev/zero で埋めたほうが良い。(/dev/zero で埋めた場合でも、ハードウェアの都合でデータを読み出せる可能性がある。詳細はディスクの完全消去を参照する。)
I/O の種別
今回は read write による同期 I/O の場合のみを説明したが、非同期 I/O もある。また mmap を使ってファイルをメモリ上にマップする方法もある。詳細はまた別の機会に。