メモリ管理は、Linux カーネルのコアな機能です。この機能を理解することで、サーバの統計情報の意味がわかるようになったり、トラブル解析ができるようになります。
この記事では、Linux カーネルのメモリ管理について勉強したことを基礎からまとめます。
時間がない人は ここ と ここ だけ読んでらえればと思います。
プロセス編はこちら。
Linux メモリ管理 徹底入門(プロセス編) - SIerだけど技術やりたいブログwww.kimullaa.com
メモリ管理はハードウェアに強く依存するため、x86_64 かつ OS起動後に 64bitプロテクトモード に移行したあとに話を絞る。また、OS は CentOS8.1、カーネルは次のバージョンを利用する。
]# cat /etc/redhat-release
CentOS Linux release 8.1.1911 (Core)
]# uname -a
Linux localhost.localdomain 4.18.0-147.3.1.el8_1.x86_64 #1 SMP Fri Jan 3 23:55:26 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
ハードウェア寄りの話
カーネルはハードウェアの機能を利用してメモリ管理を実現する。そのため、まずはハードウェアに関する知識をさらっと流す。
ノイマン型アーキテクチャ
コンピュータの基本的な構成のひとつ。次の図が参考になる。 ほぼ全てのコンピュータが、このアーキテクチャを採用している。
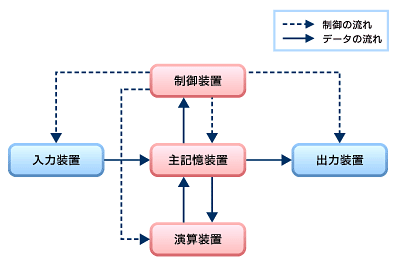
メモリ関連で大事なことは、CPU上で動作するプログラムは主記憶装置(=メモリ)を介してアクセスされるということ。何をするにも、いったんメモリを経由する必要がある。
ハードウェア構成
ご家庭用のマザーボードの典型的な構成は、次のようになっている(細かい構成はchipset のバージョンによって異なる)。
参考 Wikipedia チップセット
参考 ドスパラ チップセットとは?
|- memory
CPU -| |- hdd, ssd
|- bridge -|
|- key board
|- ...
各要素はバスという部品で接続されていて、CPU からメモリにアクセスするときもバスを利用する。最近は 1 つの CPU にたくさんのコアを積んでいる。そのため、各コアがバスを占有できるように排他制御される。
UMA
エンタープライズ向けの高性能なサーバ(HP の Gen10とか)では、CPU 自体を複数搭載できる。(これらは Xeon などのマルチソケットに対応した CPU を利用している。)
参考 「Xeon」はCore i7やi9と比べて何が違うのか?
UMA は、複数の CPU があるときに物理メモリを共有する方式のこと。メモリアクセスのためにバスを占有する必要があるため、CPU をバンバン増やしても性能が上がりづらい。
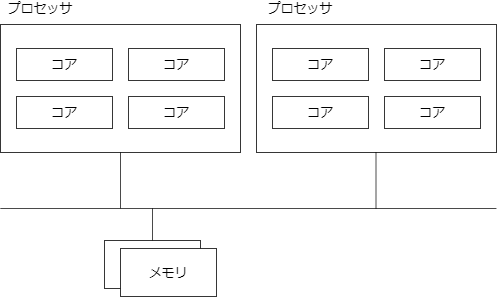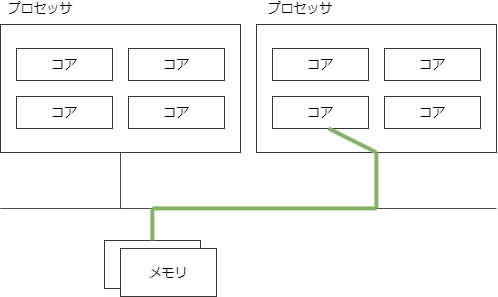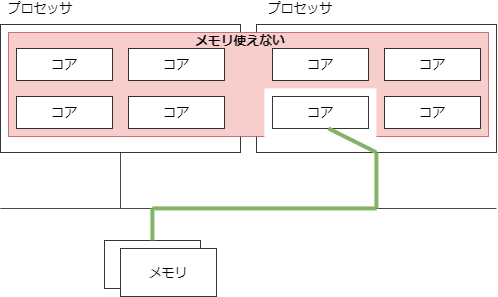
NUMA
UMA の問題を回避するためには、バスの共有を減らせばいい。
NUMA は CPUとメモリをノードごとに分けてバスの輻輳を軽減する。メモリアクセスの局所性を活かし、自分がよく使うデータを近いメモリに配置する。遠くに配置されたメモリにアクセスすることもあるが、頻度が低いので影響は少ない。
参考 NUMA DEEP DIVE PART 1: FROM UMA TO NUMA
参考 FRANKDENNEMAN.NL > NUMA
カーネルは NUMA に対応していて、単一 CPU/メモリの場合も 1ノードの NUMA として扱う。
DMA
NUMA では CPU-メモリ間の通信を考えた。ここでは、 hdd/ssd との通信を考える。古典的には hdd/ssd との通信には CPU レジスタを経由して①→②→③の順番で通信していた。(PIO)
|- memory ①
CPU(register) ② -| |- hdd, ssd ③
|- bridge -|
|- key board
|- ...
PIO の場合、データ転送中も CPU サイクルを消費する。そのため、CPU を介さずに ① から ③ に直接転送できる仕組みができた(DMA)。DMA では、DMAC に転送設定をすることで、データ転送中に CPU が別のタスクを実行できる。
参考 Wikipedia DMA
参考 uQuest DMA対応と言われたら(1)
アドレスの種類
メモリには、3種類のアドレスがある。各アドレスは CPU の MMU(Memory Management Unit) によって変換される。
参考 Wikipedia メモリ管理ユニット
論理アドレス
- マシン語で指定するときのアドレス
- セグメントセレクタとオフセットで構成される
- セグメントセレクタはセグメントレジスタ(CS/SS/DS など)に設定されている
仮想アドレス(リニアアドレス)
- 一直線にメモリを確保しているように見せるアドレス
物理アドレス
- CPUからメモリにアクセスするときのアドレス

ただし x86_64 の場合は 論理アドレス = 仮想アドレス。
参考 Linux x86_64のメモリアドレッシング
セグメント(補足)
論理アドレスと仮想アドレスを変換する仕組み。セグメントはアドレスを区画に区切ってセグメントセレクタごとにズラすために存在した。しかし、 x86_64 では基本的に無効にされている。
In 64-bit mode, segmentation is generally (but not completely) disabled, creating a flat 64-bit linear-address space. The processor treats the segment base of CS, DS, ES, SS as zero, creating a linear address that is equal to the effective address. The exceptions are the FS and GS segments, whose segment registers (which hold the segment base) can be used as additional base registers in some linear address calculations.
参考 IntelR 64 and IA-32 Architectures Software Developer’s Manual
念のためソースコードも確認していくと、セグメントセレクタとセグメントディスクリプタが次のように定義されている。
arch/x86/include/asm/segment.h
// CS はコードセグメント
// DS はデータセグメント
// このほかにも SS(スタックセグメント) などがある
#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS*8)
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS*8)
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS*8 + 3)
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS*8 + 3)
arch/x86/kernel/cpu/common.c
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff),
...
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff),
カーネルコード上も全てのセグメントディスクリプタで仮想アドレスの開始点(base)が 0 になっていて、どんなセグメントでも実アドレスがズレない。つまり論理アドレス = 仮想アドレス。
arch/x86/include/asm/desc_defs.h
#define GDT_ENTRY_INIT(flags, base, limit) \
{ \
.limit0 = (u16) (limit), \
.limit1 = ((limit) >> 16) & 0x0F, \
.base0 = (u16) (base), \
.base1 = ((base) >> 16) & 0xFF, \
.base2 = ((base) >> 24) & 0xFF, \
.type = (flags & 0x0f), \
.s = (flags >> 4) & 0x01, \
.dpl = (flags >> 5) & 0x03, \
.p = (flags >> 7) & 0x01, \
.avl = (flags >> 12) & 0x01, \
.l = (flags >> 13) & 0x01, \
.d = (flags >> 14) & 0x01, \
.g = (flags >> 15) & 0x01, \
}
ではセグメントは何のために利用しているかというと、主に特権レベルを設定するために利用している。セグメントディスクリプタの定義を確認すると、次のようになっている。DPL に特権レベルを設定すればいいことがわかる。
引用元 IntelR 64 and IA-32 Architectures Software Developer’s Manual
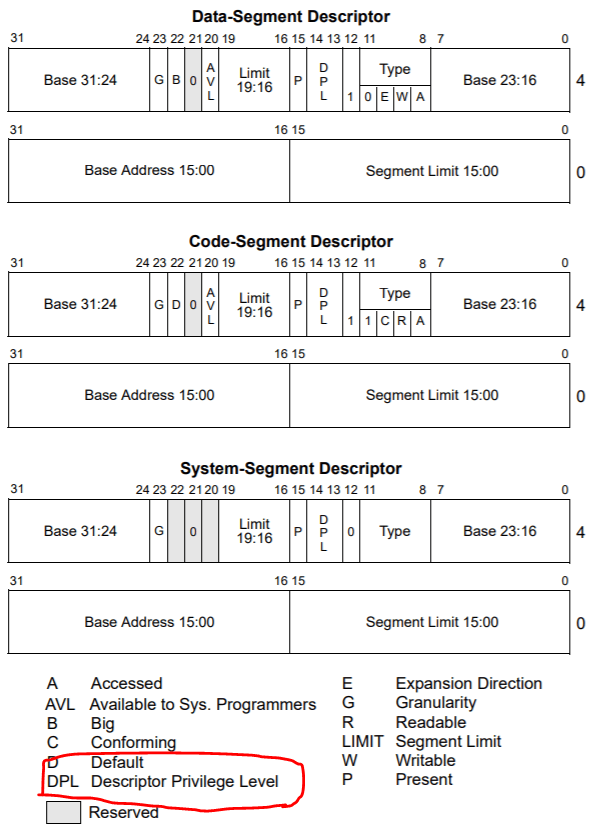
DPL に設定されている値が USER 用ディスクリプタは 3、KERNEL 用ディスクリプタは 0 になっている。これが特権レベルの制御に使われる。特権レベルについては省略する。
Linux システムコール 徹底入門 - SIerだけど技術やりたいブログwww.kimullaa.com
ページング
仮想アドレスと物理アドレスを変換する仕組み。変換を効率的に行うために、CPUはアドレス空間を固定単位(基本は4KB)で区切ったページで管理する。またメモリ効率のよい変換を実現するために、ページングを利用する。(次の図でいう 4-level)
参考 IntelR 64 and IA-32 Architectures Software Developer’s Manual
仮想アドレスから物理アドレスの変換は MMU が行う。アドレス変換はコストが高いため、 TLB(Translation Lookaside Buffer) にキャッシュされる。
参考 Wikipedia トランスレーション・ルックアサイド・バッファ
**Linux カーネルの仕事は、このデータ構造をメモリ上に用意して CR3(Control Registor 3) に設定すること。またプロセスごとに CR3 を切り替えること。**これによって、プロセスごとに独立した仮想アドレス空間を用意できる。
参考 IntelR 64 and IA-32 Architectures Software Developer’s Manual
メモリ空間を切り替えた場合、 TLB は CPU によって自動でフラッシュされる(他の人の仮想-物理メモリの対応がキャッシュされると危ないため) 。そのため、頻繁に切り替えが発生すると、メモリへのアクセス効率が落ちる。
参考 IntelR 64 and IA-32 Architectures Software Developer’s Manual の 4.10.4 Invalidation of TLBs and Paging-Structure Caches
Huge Page
TLB のキャッシュは上限があるので、小さい単位でページを作っているとキャッシュエントリ数が多くなってヒット率が上がらないことがある。この対策のひとつがHuge Page。1ページに扱うデータ量を増やすことでTLBのミスヒットを減らすことができる。ユーザプログラムが意識して実装する必要がある hugetlbpage support と、ユーザからは透過的に見える Transparet Huge Pages(THP) の 2種類の仕組みが存在する。データベースは共有バッファをうまく使うことが性能に直結するので、hugetlbpage support に対応していることが多い。
詳細は次のページを参考にする。
参考 Huge Page とは何ですか? これを使用する利点は?
参考 Huge Page まとめ
4-level-paging(補足)
4-level-paging を実現するためのデータ構造は、カーネルが管理している。カーネルでは、仮想アドレスを上から 5 つに区切っている。
- pgd(ページグローバルディレクトリ)
- pud(ページアッパーディレクトリ)
- pmd(ページミドルディレクトリ)
- pte(ページテーブルエントリ)
- offset
これがそのまま CPU の paging に対応する。
図でもわかる通り、何度も変換してようやく物理アドレスに辿りつく。「なんでこんな仕組みになっているんだ…仮想アドレスと物理アドレスの変換をするならマップでいいんじゃないの?」と思ったが、この方式はメモリの利用効率がとても良い。計算するとわかるが、仮想アドレスと物理アドレスのマップを作ったとすると、 そのマップだけで 1 プロセスあたり 274GB くらい物理メモリが必要になる。
- (決まりごと) 1ページあたり 4kB(=212) で管理する
- 仮想アドレスを 64bit 幅まるまる確保すると 264 / 212 = 252 ページ
- (決まりごと) 1 ページを管理するのに 8 Byte かかる
- 252(page) * 8(Byte/page) = 255 Byte (=274 GB )のデータ量
一般的に、プロセスはそこまで物理メモリを消費しない。そのため、実際に対応関係がある部分以外(ページ変換テーブルの大部分)は無駄になる。
そのため 4-level-paging では、物理メモリが実際に割り当てられてページ変換テーブルが必要になったときに、必要なエントリ(pgd~pte)だけを作成し、それ以外はページ変換テーブルのエントリを作成しない。このために pgd~pte 自体もページ単位で管理している。
なお、 CPU によってページングの仕組みは違う(昔は 3-level paging だった。最近の CPU では 5-level paging というのもある)。そのため、Linuxカーネルは、コード内で動作を切り替えて様々なレベルのページングに対応している。5-level paging の例は、次のリンクが参考になる。
参考 Linux kernelの5-Level Paging有効化部分を読んでみる
プロセスごとのメモリ空間の切り替え(補足)
プロセスごとにメモリ空間を切り替えるコードを追ってみる。
load_new_mm_cr3 の context_switch がコンテキストスイッチする処理。これを見ていくと、switch_mm_irqs_off という関数がある。
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
...
if (!mm) {
next->active_mm = oldmm;
mmgrab(oldmm);
enter_lazy_tlb(oldmm, next);
} else
switch_mm_irqs_off(oldmm, mm, next);
...
switch_mm_irqs_off は arch/x86/mm/tlb.c に定義されていて、この中で load_new_mm_cr3 が実行されて、プロセスごとの pgd を cr3 に設定している。
void switch_mm_irqs_off(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
...
if (real_prev == next) {
...
} else {
...
if (need_flush) {
this_cpu_write(cpu_tlbstate.ctxs[new_asid].ctx_id, next->context.ctx_id);
this_cpu_write(cpu_tlbstate.ctxs[new_asid].tlb_gen, next_tlb_gen);
load_new_mm_cr3(next->pgd, new_asid, true);
...
trace_tlb_flush_rcuidle(TLB_FLUSH_ON_TASK_SWITCH, TLB_FLUSH_ALL);
} else {
/* The new ASID is already up to date. */
load_new_mm_cr3(next->pgd, new_asid, false);
...
また最近のカーネルではユーザ空間/カーネル空間でページテーブルが分離されるようになったので、システムコールが実行された際にもページテーブルの切り替えが実行されるっぽい。
参考 kpti のパッチセット
arch/x86/entry/entry_64.S
ENTRY(entry_SYSCALL_64)
...
SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi
arch/x86/entry/calling.h
.macro SWITCH_TO_USER_CR3_STACK scratch_reg:req
pushq %rax
SWITCH_TO_USER_CR3_NOSTACK scratch_reg=\scratch_reg scratch_reg2=%rax
popq %rax
.endm
...
.macro SWITCH_TO_USER_CR3_NOSTACK scratch_reg:req scratch_reg2:req
ALTERNATIVE "jmp .Lend_\@", "", X86_FEATURE_PTI
mov %cr3, \scratch_reg
ALTERNATIVE "jmp .Lwrcr3_\@", "", X86_FEATURE_PCID
...
.Lwrcr3_\@:
/* Flip the PGD to the user version */
orq $(PTI_USER_PGTABLE_MASK), \scratch_reg
mov \scratch_reg, %cr3
.Lend_\@:
ZONE
Linux カーネルは歴史的経緯(昔あったハードウェア上の制約)により、メモリを利用用途ごとに複数のゾーンに分割している。
]# cat /proc/zoneinfo | grep "zone "
// Node は NUMA のノードのこと
Node 0, zone DMA
Node 0, zone DMA32
Node 0, zone Normal
Node 0, zone Movable
Node 0, zone Device
DMA … DMA 用のメモリ。16MB。かなり古い機器ではメモリアクセス範囲に制限があったため、専用のエリアができた。(今となっては必要性があるかはともかく)まだ利用しているドライバも多いので、なかなか削除できないらしい。
参考 lwn.net Is it time to remove ZONE_DMA?
DMA32 … 32 bit 版に拡張された DMA 用のメモリ。4GB。
参考 lwn.net ZONE_DMA32
NORMAL … カーネルやプロセスが利用する一般的な領域。
参考 Documentation/admin-guide/mm/concepts.rst
メモリ上限
CPU がメモリを利用するためには、メモリアドレスが特定できる必要がある。 したがって、利用できるメモリの理論値は、CPU のレジスタ幅に制限される(2**64=16EB)。もっとも、2**64(=16EB) は誰も使わないので、もう少し手前で物理的に制限されている。CPU としてどこまでサポートしてるのかはCPUアーキテクチャごとにも異なるため、各種マニュアルを参照すること。x86_64 では、仮想アドレスは 2**64 bytes まで利用できるが、物理アドレスは 2**52 bytes に制限されている。
A task or program running in 64-bit mode on an IA-32 processor can address linear address space of up to 2**64 bytes (subject to the canonical addressing requirement described in Section 3.3.7.1) and physical address space of up to 2**52 bytes.
参考 IntelR 64 and IA-32 Architectures Software Developer’s Manual
またカーネルとしても、実装上の都合でメモリの上限がある。
参考 Documentation/x86/x86_64/mm.txt
動作確認済みのメモリ上限を各ディストリビューターから提示していることもあるので、サポート付きのOSを使うときはこれに従うべきだと思う。(例えば RHEL7 では 12TB まで動作が保証されているが、 RHEL8 では 24TB まで動作が保証されている)
参考 Red Hat Enterprise Linux technology capabilities and limits
メモリ空間
Linux でのメモリ空間の使い方は CPU アーキテクチャごとに異なる。 x86_64 では次のように使う。
Virtual memory map with 4 level page tables:
0000000000000000 - 00007fffffffffff (=47 bits) user space, different per mm
hole caused by [47:63] sign extension
ffff800000000000 - ffff87ffffffffff (=43 bits) guard hole, reserved for hypervisor
ffff880000000000 - ffffc7ffffffffff (=64 TB) direct mapping of all phys. memory
ffffc80000000000 - ffffc8ffffffffff (=40 bits) hole
ffffc90000000000 - ffffe8ffffffffff (=45 bits) vmalloc/ioremap space
ffffe90000000000 - ffffe9ffffffffff (=40 bits) hole
ffffea0000000000 - ffffeaffffffffff (=40 bits) virtual memory map (1TB)
... unused hole ...
ffffec0000000000 - fffffbffffffffff (=44 bits) kasan shadow memory (16TB)
... unused hole ...
vaddr_end for KASLR
fffffe0000000000 - fffffe7fffffffff (=39 bits) cpu_entry_area mapping
fffffe8000000000 - fffffeffffffffff (=39 bits) LDT remap for PTI
ffffff0000000000 - ffffff7fffffffff (=39 bits) %esp fixup stacks
... unused hole ...
ffffffef00000000 - fffffffeffffffff (=64 GB) EFI region mapping space
... unused hole ...
ffffffff80000000 - ffffffff9fffffff (=512 MB) kernel text mapping, from phys 0
ffffffffa0000000 - fffffffffeffffff (1520 MB) module mapping space
[fixmap start] - ffffffffff5fffff kernel-internal fixmap range
ffffffffff600000 - ffffffffff600fff (=4 kB) legacy vsyscall ABI
ffffffffffe00000 - ffffffffffffffff (=2 MB) unused hole
参考 Linuxカーネルソースコード Documentation/x86/x86_64/mm.txt
主な特徴は次の通り。
仮想アドレス上はユーザとプロセスのメモリが連続している。(ただしプロセスからカーネルのメモリ空間は見れないように制御されている)
ユーザ空間はプロセスごとに切り替わる
~~メモリのコンテキスト切り替えのコストを下げるために(CR3切り替えをしなくて済むように/TLBキャッシュが効くように)、連続したメモリ空間上にカーネルのメモリをマップしている。カーネルは独自のページテーブルを持たず、切り替え前のプロセスのページテーブルを利用する。~~最近のカーネルバージョンでは Spectre/Meltdown 脆弱性の対策(KPTI)で、ユーザ空間/カーネル空間でページテーブルが分離されるようになっている。
参考 KAISER: hiding the kernel from user space
参考 The current state of kernel page-table isolation
参考 Wikipedia Kernel page-table isolationストレートマップという仮想アドレスと物理アドレスが 1:1 に対応する領域がある。プロテクトモードでは、仮想アドレスを通してのみメモリにアクセスできる。カーネルはどんな物理アドレスにもサッとアクセスする必要があるので、仮想アドレスと物理アドレスを 1:1 に対応づけている。(なのでプロセスが利用してる物理メモリがストレートマップ領域からもアクセスできるようになってる)

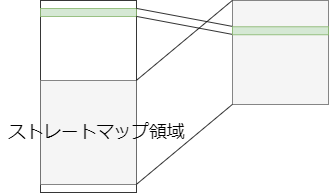
そのほかにもいろいろと特徴があるがまだ調べきれてない。そのうち追加する。
メモリの利用方針
カーネルはざっくりと(本当にざっくりと)、次の方針でメモリを利用する。
メモリに余裕がある限り、回収せずにじゃぶじゃぶ使う。
余裕がなくなってきたらメモリを回収する。
プロセス
- 要求されたメモリは、すぐに必要になるかわからない。そのため、実際にメモリを利用するまで割り当てを遅延する。(デマンドページング)
- 連続した実メモリを必要としない。
カーネル
- 要求されたメモリは、すぐに割り当てる。
- 連続したメモリを必要とすることもある。
メモリの獲得
カーネルはメモリの獲得方法をいろいろ用意している。まず全体像を示す。
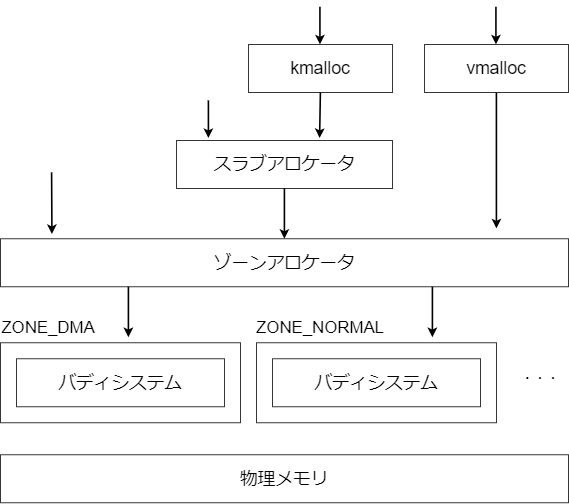
物理メモリの獲得はゾーンアロケータが一元管理する。またメモリの使い方ごとに、さまざまなインタフェースが用意されている。それぞれの差について説明する。
ゾーンアロケータ
- メモリ割り当て処理のフロントエンド(
alloc_pages(gfp_mask, order)) - 各ゾーンの中から要求を満たすゾーンを見つけてメモリを獲得する(ただし、貴重なゾーンは節約したりというコントロールを行う)
- メモリの空きが少なくなったら回収処理をする
- カーネル内の様々な場所でよびだされる(メジャーなものは、ページキャッシュやページフォールト例外発生時。デマンドページングは仮想アドレスだけ与えておき、ページフォールト例外が発生したときに実メモリを 1 ページ分獲得することで実現している。)
ページ回収
回収処理は、ゾーンごとに用意された次のしきい値を利用する。
]# cat /proc/zoneinfo
Node 0, zone Normal
pages free 12759
min 8722
low 10902
high 13082
...
図にすると次のようになる。
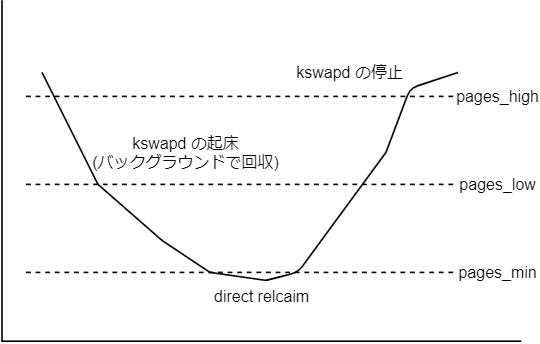
- pages_low を下回ったら kswapd を起動する
- kswapd はバックグラウンドでメモリを回収する
- pages_high を上回ったら kswapd を停止する
- pages_min を下回ったらメモリを同期的に回収してから割り当てる
※ しきい値判定はフラグによってじゃっかん上下する。
ということは、メモリの割り当てに失敗することはないように思える(メモリが少なくなったら、メモリを同期的に回収してから割り当てるため)。しかし、割込みコンテキストでメモリを要求された場合、とにかく早さ重視でメモリを回収せずにバンバン割り当てるため、実際にはメモリ割り当てに失敗することがある。例えば、パケットがバースト的に到着したりしてメモリ獲得を連発された場合などに、page allocation failure が発生する可能性がある。(連続した空きメモリが足りないなど)
回収時の処理
回収時に必要な処理は、メモリの使われ方によって異なる。
File Backed
- 実体がファイルシステム上に存在するもの
- 主に mmap で確保されるメモリやファイルキャッシュ
- メモリ上のデータが更新されるとファイルと乖離が出る(=Dirty)
- メモリを解放するときは、 Dirty なものをディスクに書き出す必要がある
- Dirty でなければディスク I/O なしで回収できる
- なるべく回収時に Dirty なページが残ってないように flusher スレッドが定期的に同期する。詳細はこちらを参照してください。 Linux ファイルシステム 徹底入門 - SIerだけど技術やりたいブログwww.kimullaa.com
Anonymous
- 実体がファイルシステム上に存在しないもの
- 主にデータ領域やヒープ領域
- メモリを開放するときは、スワップアウトする必要がある
- スワップアウト = 絶対にダメ! ではない(たまにしか動かないプロセスのデータがメモリ上に常駐してても意味がない)
どちらを優先して回収するかは、 swappiness で調整できる。
参考 Linuxのswappinessは本当にスワップしにくさを設定できるのか
またこれ以外にも、カーネルの slab やカーネルモジュールが回収対象になるが、これらのメモリは各コンポーネントに回収依頼をする形になる(リーピング)。
File Backed な動作を確かめる
次のコマンドを実行し、メモリサイズより大きなファイルを作成する。
]# dd if=/dev/zero of=/home/large count=100000000 bs=100
ある程度までページキャッシュとして使い続け、メモリが不足してきたころにキャッシュを回収しつつ動作する様子が確認できる。またこのキャッシュは、プロセスが停止しても残り続ける。
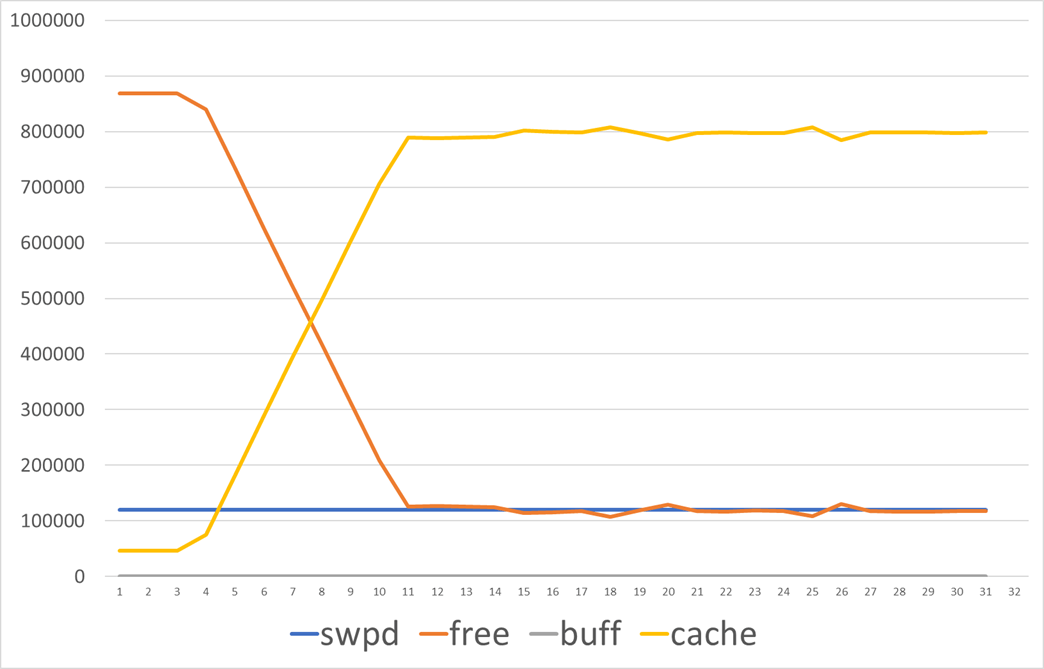
少し脱線して…
こういう挙動をみると、一度しか使わない大きめファイルを気軽に読み書きするのはキャッシュ効率の面で悪いですね。せっかくの有効なキャッシュも追い出しちゃいますからね。たとえばバックアップで 10GB のファイルを cp したら、それだけでコピー元とコピー先で 20GB のページキャッシュ使いますもんね。もうバックアップ取ったら使わないのにね。ということでページキャッシュに入れずに I/O ができる direct I/Oはこういうケースで良い選択肢なんでしょう。まあ cp は対応してないんですけども。
Anonymous な動作を確かめる
次のコマンドを実行し、0.1 秒ごとに 1GB の Anonymous メモリを獲得するプロセスを起動する。15 秒経ったらプロセスを終了する。
]# cat swap.sh
#!/bin/bash
for i in $(seq 1 100)
do
sleep 0.1
/tmp/stress-ng/stress-ng -vm 1 --vm-bytes 100000000 --vm-hang 1000 &
done
]# swap.sh
こちらもある程度までメモリを使い続け、メモリが不足してきたころに回収しつつ動作する様子が確認できる。ただし Anonymous なメモリはスワップアウトするときに確実にディスク I/O が発生する。また、プロセス固有のデータはプロセスが終了したら回収される。
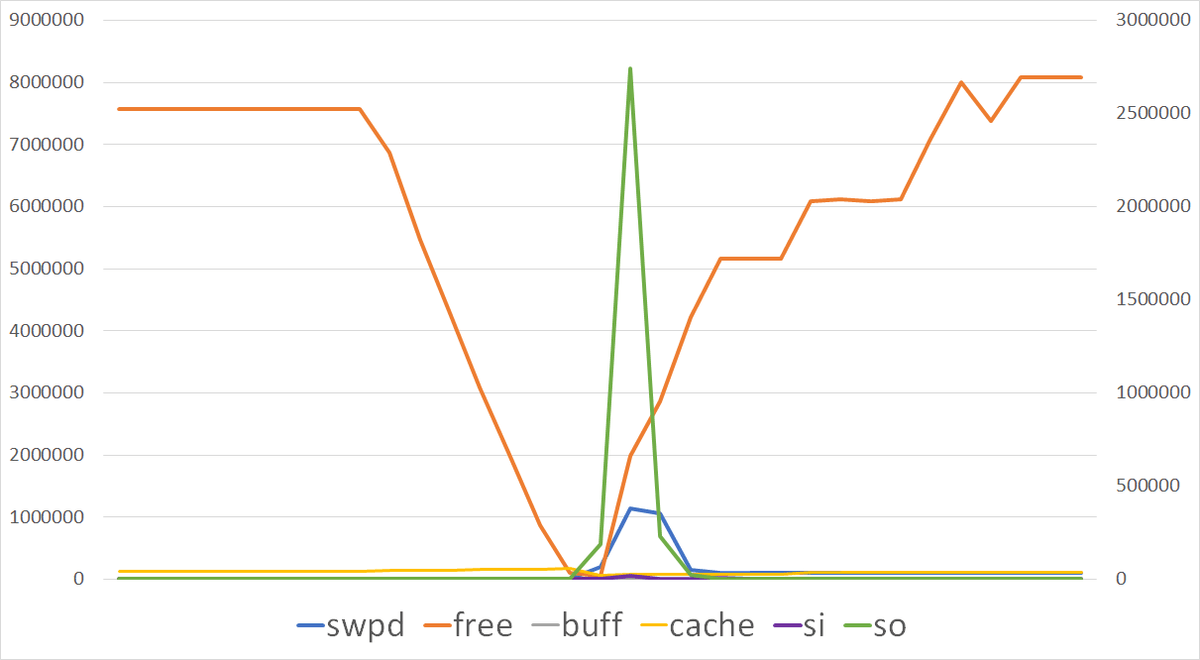
OOM Killer
メモリがどうしても回収できない場合(File Backed はディスクに書き出せばメモリを回収できるが、Anonymous なページがメモリ利用の大半でありスワップ領域が埋まってる場合、追い出し先がないためメモリが回収できない。)に OOM Killer が実行される。OOM Killer は、メモリを無理やりあけるために適当なプロセスを選択して強制的に終了させる。メモリ不足によるカーネルクラッシュを避けるための最終手段。実行されたときは次のようなメッセージが出力される。
]# dmesg
...
[14025.712413] Out of memory: Kill process 22154 (stress) score 66 or sacrifice child
[14025.712415] Killed process 22154 (stress) total-vm:1055888kB, anon-rss:1048648kB, file-rss:0kB, shmem-rss:0kB
ページ回収の仕組みからメモリ使用率を考える
これまでの説明の通り、Linux は余裕がある限りメモリをじゃぶじゃぶ使う。そして不足したころに回収する。
メモリ使用率は時間とともに常に高くなるのが当たり前。そのため、性能指標としてメモリ使用率を監視するのはあまり意味がない。じゃあ何を監視に使うかというと、回収可能な領域(Available)がどれだけあるか、や、スワップインが頻発してないか、じゃないかと思う。Available は、上記の回収可能な領域を勘定した値を表示してくれる。ただしアプリケーションはページキャッシュなどを活用して性能を出しているので、 Available に余裕があるけど回収時にキャッシュが追い出されて性能出なくなりました、という可能性はゼロではない。
]# cat /proc/meminfo | grep MemAvailable
MemAvailable: 670988 kB
バディシステム
- なるべく断片化を防ぎつつ、連続した実ページを確保する仕組み。
- 2のべき乗単位でページを管理する。
- メモリを割り当てるときは、要求されたサイズを満たす最小のブロックを返す。
- メモリがリリースされたときは、同じ大きさのブロックの中で連続したメモリがあれば、より大きなブロックにマージする(21 と 21 が連続してたら 22 にする)
参考 筑波大学 メモリ管理、Buddyシステム、kmalloc、スラブアロケータ
ページの情報は /proc/buddyinfoで確認できる。ここを見ると、断片化してるか(小さなページしか残ってない)がわかる。メモリに余裕があったとしても、要求された連続サイズが獲得できない場合は、page allocation failure になる。
]# cat /proc/buddyinfo
Node 0, zone DMA 0 0 0 1 2 1 1 0 1 1 3
Node 0, zone DMA32 1809 1882 802 648 306 97 15 6 2 2 0
Node 0, zone Normal 476 892 407 130 93 71 37 5 3 0 0
スラブアロケータ
バディシステムはページ単位(通常は 4KB)でメモリを獲得する。しかしカーネル内では 4KB よりも小さい単位でメモリが必要なことも多く、また、同じ構造体を高頻度で要求することも多い。これらの要求を満たす仕組みがスラブアロケータ。
参考 Linux Kernel ~ メモリ管理 スラブアロケータ編 ~
参考 スラブアロケータで始めるLinuxカーネル開発
同じ種類の構造体をあらかじめキャッシュしておくことで、メモリの 割り当て/回収コスト を効率化する。またメモリの断片化を防ぐ効果もある。
slab の状況は/proc/slabinfoなどで確認できる。
]$ cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
...
inode_cache 17255 18040 592 55 8 : tunables 0 0 0 : slabdata 328 328 0
dentry 135954 135954 192 42 2 : tunables 0 0 0 : slabdata 3237 3237 0
...
ファイルシステムの dentry あたりはヘビーユーザじゃないかと思う。dentry については次の記事も参考にしてください。
Linux ファイルシステム 徹底入門 - SIerだけど技術やりたいブログwww.kimullaa.com
kmalloc
kmalloc は任意のサイズのメモリを確保する(void *kmalloc(size_t size, gfp_t flags))。適当なサイズでスラブオブジェクトを作っておき、要求されたメモリサイズを満たす最小のものを返す。
]$ cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
...
kmalloc-8k 230 240 8192 4 8 : tunables 0 0 0 : slabdata 60 60 0
kmalloc-4k 735 808 4096 8 8 : tunables 0 0 0 : slabdata 101 101 0
kmalloc-2k 423 432 2048 8 4 : tunables 0 0 0 : slabdata 54 54 0
kmalloc-1k 1260 1512 1024 8 2 : tunables 0 0 0 : slabdata 189 189 0
kmalloc-512 1040 1248 512 8 1 : tunables 0 0 0 : slabdata 156 156 0
kmalloc-256 1336 1488 256 16 1 : tunables 0 0 0 : slabdata 93 93 0
kmalloc-192 1468 1743 192 21 1 : tunables 0 0 0 : slabdata 83 83 0
...
vmalloc
vmalloc は任意のサイズのメモリを確保する(void *vmalloc(unsigned long size))。kmalloc とは違って、獲得したメモリは物理的に連続しているとは限らない。実装としては 1 ページの物理メモリを要求されたメモリサイズになるだけ繰り返し確保する。これを仮想アドレスに紐づけることで、仮想的に連続したメモリを確保している。
vmlalloc の割り当て状況は /proc/vmallocinfo で確認できる。
]# cat /proc/vmallocinfo | head
0x00000000f7017e6b-0x000000009a491851 8192 acpi_os_map_iomem+0x1a0/0x1c0 phys=0x00000000f7ff8000 ioremap
0x000000009a491851-0x00000000c3bfd4d2 8192 acpi_os_map_iomem+0x1a0/0x1c0 phys=0x00000000f7ffe000 ioremap
0x00000000c3bfd4d2-0x000000000807a64c 8192 acpi_os_map_iomem+0x1a0/0x1c0 phys=0x00000000f7ff7000 ioremap
0x000000000807a64c-0x000000004b576a40 8192 acpi_os_map_iomem+0x1a0/0x1c0 phys=0x00000000f7ff6000 ioremap
0x000000004b576a40-0x0000000091ece1da 8192 acpi_os_map_iomem+0x1a0/0x1c0 phys=0x00000000f7ff5000 ioremap
0x0000000091ece1da-0x000000007a2fd7be 8192 acpi_os_map_iomem+0x1a0/0x1c0 phys=0x00000000f7ff4000 ioremap
0x000000007a2fd7be-0x00000000ac9275a0 8192 acpi_os_map_iomem+0x1a0/0x1c0 phys=0x00000000f7ff3000 ioremap
0x00000000ac9275a0-0x000000000aa95dd9 8192 acpi_os_map_iomem+0x1a0/0x1c0 phys=0x00000000f6dd6000 ioremap
0x000000000aa95dd9-0x00000000eb238216 8192 hv_cpu_init+0xe1/0x100 pages=1 vmalloc N0=1
0x00000000eb238216-0x000000003c6231bf 8192 hyperv_init+0x123/0x29a pages=1 vmalloc N0=1
ちなみに vmalloc もデマンドページングされる(arch/x86/mm/fault.c#vmalloc_fault)。これはプロセスに対するデマンドページングとはじゃっかん意味が異なる。そもそもは、カーネルがプロセスのページテーブルに相乗りしてたので、カーネルの領域がプロセスごとに異なっていた。そのため、1つのプロセスで vmalloc して仮想アドレスと物理アドレスを対応付けても、その対応は別のプロセスに反映されない。したがってマスタカーネルページテーブル(init_mm.pgd) だけを更新しておき、ページフォールトが発生したときにプロセスごとのページ変換テーブルにコピーしていた。実メモリはすでに確保してあるが、それを仮想アドレスに対応づけるのを遅延させる、たぶん。
参考
以下の書籍やサイトを参考にした。