プロセスについて学習したことをまとめました。間違いあればコメントください。
検証環境
CentOS 8.1 を利用する。
]$ cat /etc/redhat-release
CentOS Linux release 8.1.1911 (Core)
]$ uname -a
Linux process-test 4.18.0-147.5.1.el8_1.x86_64 #1 SMP Wed Feb 5 02:00:39 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
プロセスとは
プロセスとは、プログラムを実行したときに生成されるインスタンス。ps で表示されるやつ。
]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 180744 13272 ? Ss 22:46 0:01 /usr/lib/systemd/systemd --switched-root --system
--deserialize 18
root 2 0.0 0.0 0 0 ? S 22:46 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< 22:46 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< 22:46 0:00 [rcu_par_gp]
root 6 0.0 0.0 0 0 ? I< 22:46 0:00 [kworker/0:0H-kblockd]
root 8 0.0 0.0 0 0 ? I< 22:46 0:00 [mm_percpu_wq]
root 9 0.0 0.0 0 0 ? S 22:46 0:00 [ksoftirqd/0]
root 10 0.0 0.0 0 0 ? I 22:46 0:00 [rcu_sched]
root 11 0.0 0.0 0 0 ? S 22:46 0:00 [migration/0]
...
プロセス空間
プロセスは独立したメモリ空間を持ち、次のようにメモリを利用する。命令とデータが含まれる。
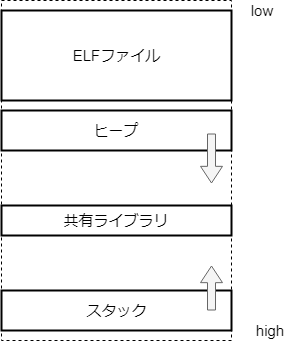
これらはプロセスごとに独立したメモリ空間になっていて、基本的に他のプロセスから影響を受けない。
※ プロセスのメモリについて詳細を知りたい方は、以前書いた記事も参照してください。
Linux メモリ管理 徹底入門(プロセス編) - SIerだけど技術やりたいブログwww.kimullaa.com
プログラムはどのように動作するか
プログラムはメモリ上にある命令(主に ELF ファイルの .text 領域)を上から順に実行する。データはレジスタやメモリを経由して受け渡し、また実行中に変化していく。大まかな流れを記述する。
- プログラムをメモリ上に展開する。
- CPU がメモリから命令を取り出す(IP レジスタを利用する)
- 命令を実行して IP レジスタを次に進める
- 関数の引数や戻り値には eax/ecx などの汎用レジスタを利用する
- ローカル変数にはスタックを利用する(SP レジスタを利用する)
- 実行中に発生するデータにはヒープを利用する
つまり、メモリと CPU が協調してプログラムは動作する。
タイムシェアリング
プログラムは厳密には CPU コア数までしか同時に実行できない。
たとえば 1 コアの場合、同時に実行できるプロセスの最大数は 1。(※ Linux ではスレッドもプロセスの一種として実装されているため、プロセスとスレッドを明確に区別せずに記載する。)
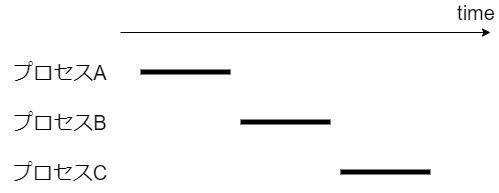
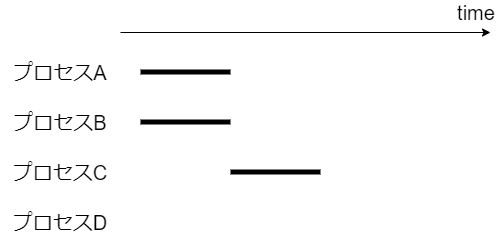
2 コアの場合、同時に実行できるプロセスの最大数は 2。ただし、プログラムの作りが悪いとコアは余る可能性がある。
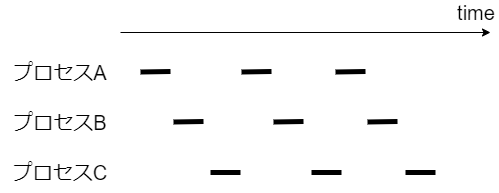
しかし実際には、コア数を意識しなくても複数のプロセスがあたかも同時に実行できる。これは、カーネルが次の図のように短時間で実行プロセスを切り替えて、疑似的に複数のプログラムが動作してるように見せているため。
どうやって実行するプロセスを切り替えるか?
プログラムはメモリと CPU が協調して動作する。メモリには特殊レジスタを介してアクセスするため、CPU レジスタの情報を入れ替えればよい。大まかな流れは次のとおり。
- (現在実行しているプロセス) CPU レジスタの値をメモリ(struct thread_info)やカーネルモードスタックに退避する
- (次に実行したいプロセス) 退避していた値を CPU レジスタに設定する
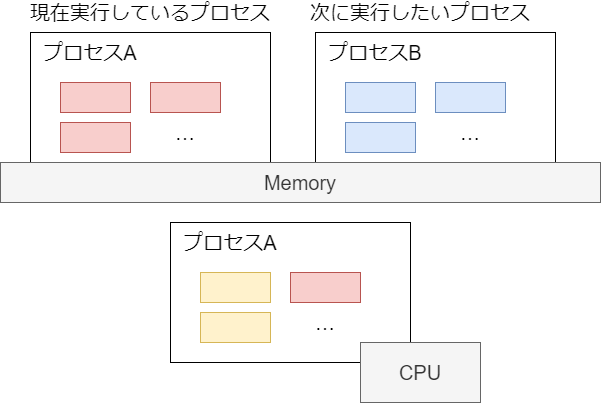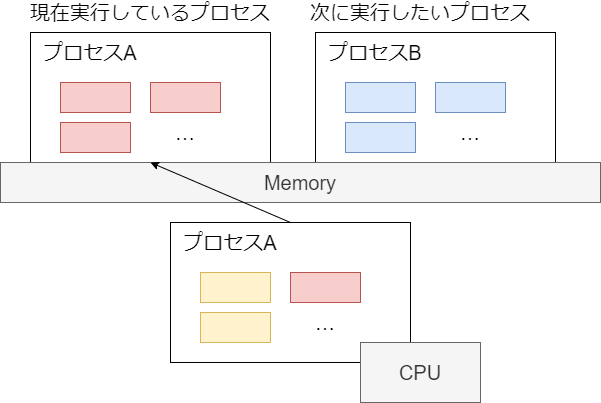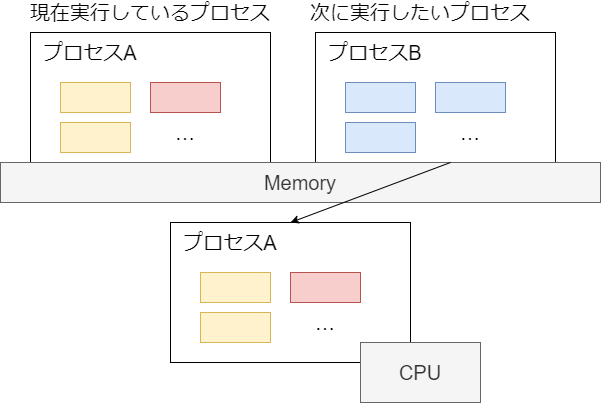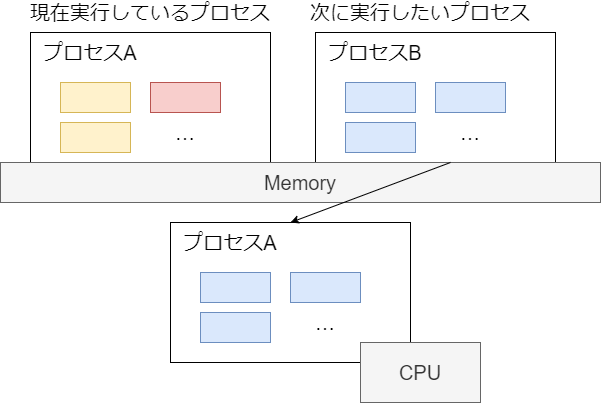
この切り替え作業をコンテキストスイッチという(kernel/sched/core.c#context_switch)。どのくらい発生しているかは vmstat の cs で確認できる。
]$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 2874612 3124 523636 0 0 120 87 60 126 1 1 97 0 0
0 0 0 2874472 3124 523676 0 0 0 0 44 102 0 1 99 0 0
0 0 0 2874472 3124 523676 0 0 0 0 36 70 0 0 100 0 0
0 0 0 2874504 3124 523676 0 0 0 0 33 66 0 0 100 0 0
...
※ カーネルが動作するときもコンテキストの切り替えは発生するが、vmstat の cs(というか /proc/stat の ctxt)には反映されないっぽい。(/proc/stat の ctxt は kernel/sched/core.c#nr_context_switches から取得しているが、この値のインクリメントが kernel/sched/core.c#__schedule だけで行われていた)。システムコールについては、以前書いた記事も参照してください。
Linux システムコール 徹底入門 - SIerだけど技術やりたいブログwww.kimullaa.com
いつプロセスを切り替えるか?
おおまかには、次のような条件でプロセスを切り替える。
プロセスが自発的に実行権を手放す
- イベントの待ち合わせ(ストレージの I/O 待ち、ソケットの受信待ち)
- シグナルの待ち合わせ、など
カーネルが強制的に実行権を取り上げる(プリエンプション)
- 割り当て時間を使いきった
- 優先度の高いプロセスが生成された、など
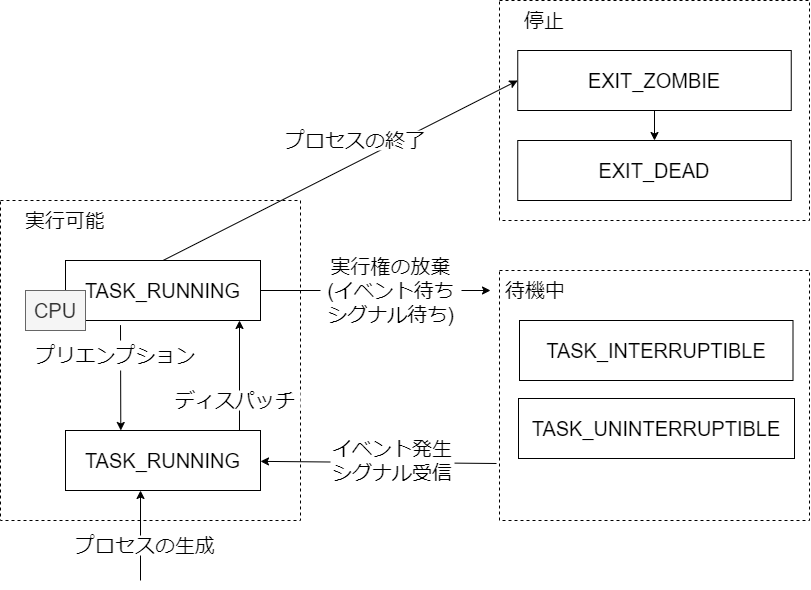
TASK_RUNNING
- CPU 上で実行されている、あるいは実行待ち
- メモリアクセス待ちは CRU 実行中としてカウントされるので別プロセスは実行できない
TASK_INTERRUPTIBLE
- 待機中。システム資源の解放、シグナル受信によりプロセスは起きる。
- ex. パケット到着待ち
TASK_UNINTERRUPTIBLE
- 待機中。TASK_INTERRUPTIBLE とほぼ同様だが、シグナルを受信しても無視する。
- ex. ディスク I/O 待ち
EXIT_ZOMBIE
- プロセスの実行終了。後述する。
- 親プロセスが wait4/waitpid システムコールを実行する前。
EXIT_DEAD
- プロセスの実行終了。
- 親プロセスが wait4/waitpid システムコールを実行した後。
そのほかにも様々な状態があるが、今回は省略する。詳細は include/linux/sched.h を参照する。
どのように割り当て時間を管理するか?
定期的にタイマー割込みを上げて、割り当て時間を過ぎていないかチェックする(kernel/sched/core.c#scheduler_tick)。
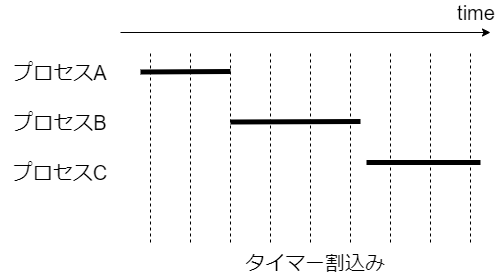
※ 割り当てる時間や切り替えるプロセスの優先度はスケジューラごとに実装が異なるので今回は言及しない(できない)。Linux では通常は割り当て時間が終わるとプロセスが切り替わってしまうため実行時間の保証が難しい。そこで、自ら実行権を開放するか、より優先度の高いプロセスが現れるまで実行し続けられる仕組み(リアルタイムプロセス)も存在する。
はるか昔は CPU がアイドル状態でもタイマー割込みを上げていたが、この場合、割込み処理のために CPU がスリープできなくて無駄な電力を消費する。また CPU がアイドル状態じゃなくても、定期的な割込み処理があると、実行時間にゆらぎが出てリアルタイムプロセスやハイパフォーマンスコンピューティングで困る。そのため最近は、タイマー割込みをなるべく上げないようになっている(tickless)。といってもいくつかの設定があり、程度は異なる。
参考 Documentation/timers/NO_HZ.txt
参考 Status of Linux dynticks
CONFIG_NO_HZ=y: CPU がアイドルの場合、割込みを上げない。CONFIG_NO_HZ_FULL=y: 実行可能なタスクが 1 つしかない場合、あるいは、CPU がアイドルの場合、割込みを上げない。ブートオプションでnohz_full=で CPU コアを指定すると有効になる。
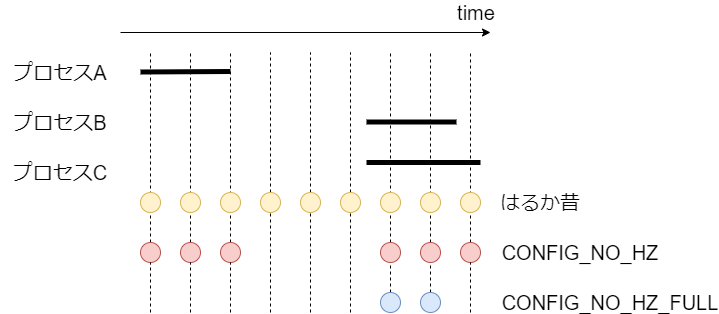
CONFIG_NO_HZ_FULL=y を実際に利用するときは、 1 コアは時刻更新などのために本設定を無効にする、などの注意点がいくつかある。詳細は Documentation/timers/NO_HZ.txt を参照する。LinuxのFull ticklessを試してみたもわかりやすい。
CentOS 8 ではどちらも有効でビルドされていたが CONFIG_NO_HZ_FULL=y はブートオプションを設定しないと意味ないので CONFIG_NO_HZ=y だけが有効だと思う。今回は CONFIG_NO_HZ=y によって CPU がアイドルのときにタイマー割込み回数が抑えられることを確認する。
ビジーループを発生させるプログラムを用意し、1 コア環境で実行する。
#!/usr/bin/env python3
while True:
pass
すると、CPU が暇なときはタイマー割込みが減っていることがわかる。
// ビジーループあり
]$ cat /proc/interrupts | grep Local ; sleep 1 ; cat /proc/interrupts | grep Local
LOC: 182964 Local timer interrupts
LOC: 183993 Local timer interrupts
// ビジーループなし
]$ cat /proc/interrupts | grep Local ; sleep 1 ; cat /proc/interrupts | grep Local
LOC: 176202 Local timer interrupts
LOC: 176239 Local timer interrupts
なお、タイマー割込みは、最大で CONFIG_HZ の頻度で発生する。(CentOS 8 だとデフォルトは 1000 HZ = 1秒間に 1000 回)。今回は雑な検証なのでプロセス生成に時間がかかったりして誤差がでているが、ビジー状態だと CONFIG_HZ とほぼ同じという事もわかる。
プロセス切り替えの仕組みは kernel/sched/core.c#resched_curr で TIF_NEED_RESCHED を設定するだけ。すると、次のユーザーモード切り替え時に kernel/sched/core.c#schedule でプロセスが切り替わる。
ランキュー
CPU ごとに管理されてるタスクの集合。ランキューといいつつキューとは限らない。
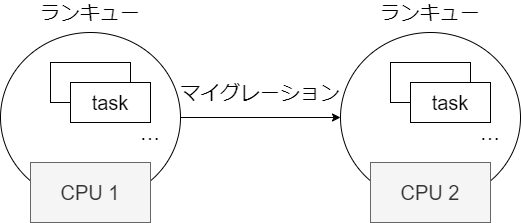
次の理由から、タスクは CPU ごとに管理されている。
- CPU にはキャッシュがあるため、タスクは同一の CPU で処理したほうが効率が良い
- CPU 間の共有リソースは排他制御が高コスト
どの ランキューに入るかは fork したときに決まる。実装はスケジューラごとに異なるので以下略。ただし、タスクが待機状態になったあとに再度 TASK_RUNNABLE になったときに、他の CPU にマイグレーションする可能性がある(kernel/sched/core.c#try_to_wake_up から select_task_rq と set_task_cpu が呼ばれて migrate_task_rq が実行される)。一般的には負荷のかたよりが大きくなってきたらマイグレーションすると思うが、実装はスケジューラごとに異なるので以下略。また、タスクの affinity が変更されたときや、CPU の Hot Plug を利用して CPU が減らされたときもマイグレーションされる。そのほかにも CFS class は scheduler_tick 実行時にバランシング処理が入ってマイグレーションするようだけど、個別のスケジューラを読み解くのは時間的に厳しいので以下略(Documentation/scheduler/sched-domains.txt を参照するとよさそう。また Linux スケジューラーのコア実装とシステムコール も詳しそう。)
ライフサイクル
プログラムは大まかに fork -> exec で実行する。
fork はプロセスのコピー(Linux では一般的に clone システムコールを使う)
- 親プロセスを複製する
exec はプロセスの実行(内部的には execve や execveat システムコールを使う)
- 実行したいプログラム用に書き換える
bash で ls を実行したときの様子を strace で確認しても、fork -> exec の流れだとわかる。
terminal A]$ echo $$
1962
// terminal A の bash プロセスにアタッチする
terminal B]$ strace -p 1962 -f -e clone,execve
strace: Process 1962 attached
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7f6ba1b2ca10) = 4292
strace: Process 4292 attached
[pid 4292] execve("/usr/bin/ls", ["ls", "--color=auto"], 0x559535a602d0 /* 26 vars */) = 0
[pid 4292] +++ exited with 0 +++
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=4292, si_uid=1000, si_status=0, si_utime=0, si_stime=0} -
--
ただし、プログラムによっては fork のみの場合もある。(たとえば apache が子プロセスを fork するとか)
init デーモン
fork でプロセスを生成するということは、全てのプロセスの親を辿っていくと同じプロセスにたどり着く。これが init デーモンであり、CentOS 8 では systemd が利用されている。
プロセスの親子関係を pstree で表示すると、自分の環境では次のようになった。
]$ sudo pstree
systemd─┬─NetworkManager───2*[{NetworkManager}]
├─2*[agetty]
├─anacron
├─auditd───{auditd}
├─chronyd
├─crond
├─dbus-daemon───{dbus-daemon}
├─firewalld───{firewalld}
├─google_guest_ag───8*[{google_guest_ag}]
├─google_osconfig───7*[{google_osconfig}]
├─polkitd───5*[{polkitd}]
├─rngd───{rngd}
├─rsyslogd───2*[{rsyslogd}]
├─sshd─┬─sshd───sshd─┬─bash───sudo───pstree
│ │ └─sftp-server
│ └─sshd───sshd─┬─bash
│ └─sftp-server
├─sssd─┬─sssd_be
│ └─sssd_nss
├─systemd───(sd-pam)
├─systemd-journal
├─systemd-logind
├─systemd-resolve
├─systemd-udevd
└─tuned───3*[{tuned}]
なお、すべてのプロセスの親である init デーモンは、カーネル上で特別扱いされている。
- カーネルが直接プロセスを起動する(init/main.c#kernel_init で /sbin/init を起動する)
- 親プロセスが死んだプロセス(孤児プロセス)は init の子プロセスになる(kernel/exit.c#forget_original_parent)
- SIGKILL などのシグナルが無視される(kernel/fork.c#copy_process で SIGNAL_UNKILLABLE を設定する)
- init デーモンが停止する場合、panic を起こして強制終了する(kernel/exit.c#find_child_reaper)
動作確認できるものだけ確認する。
まず、pid=1 は SIGKILL が無視される。
]$ LANG=C date
Tue Apr 7 01:43:54 UTC 2020
]$ sudo kill -SIGKILL 1
// pid 1 が生きている、かつ、起動時刻がかなり前(再起動したわけではない)
]$ ps -eo pid,lstart,cmd
PID STARTED CMD
1 Mon Apr 6 22:46:54 2020 /usr/lib/systemd/systemd --switched-root --system --deserialize 18
...
また、孤児プロセスは systemd の子になる。次のように、 5s 後に孤児プロセスになるプログラムを用意する。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(void) {
int pid;
if ((pid =fork()) == 0) {
sleep(10);
// child died
} else {
sleep(5);
// parent died
}
}
実行直後と親が死んで孤児プロセスになった後を比較すると、孤児プロセスが systemd に引き取られているのがわかる。
]$ gcc -o main main.c
]$ ./main
// 実行直後
]$ pstree
systemd─┬─NetworkManager───2*[{NetworkManager}]
...
├─sshd─┬─sshd───sshd─┬─bash───main───main
...
// 親が死んで孤児プロセスになった後
]$ pstree
systemd─┬─NetworkManager───2*[{NetworkManager}]
...
├─main
...
Zombie プロセス
wait システムコールの規約では、親プロセスは子プロセスの終了状態(exit コードなど)を取得できる。
All of these system calls are used to wait for state changes in a child of the calling process, and obtain information about the child whose state has changed. A state change is considered to be: the child terminated; the child was stopped by a signal; or the child was resumed by a signal.
たとえば、次のようなコードを用意し
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(void) {
int pid;
if ((pid = fork()) == -1) {
perror("fork failed");
// 子プロセスで sleep 5 する
} else if (pid == 0) {
execl("/usr/bin/sleep", "/usr/bin/sleep", "5", NULL);
// parent で子プロセスの終了を待って exit code を出力する
} else {
int status;
waitpid(pid, &status, 0);
if (WIFEXITED(status)) {
printf("child's exit code is %d \n", WEXITSTATUS(status));
}
}
}
実行すると子プロセスの exit code が取得できる。
]$ gcc main.c -o main
]$ ./main
child's exit code is 0
これを実現するためには、親が子の状態を取得するまで停止状態を保管する必要がある。つまり子プロセスの処理が終了しても、wait が呼ばれない限りはプロセスがリソースを開放しきれない(Zombie)。
In the case of a terminated child, performing a wait allows the system to release the resources associated with the child; if a wait is not performed, then the terminated child remains in a “zombie” state (see NOTES below).
引用元: man page of wait
具体的にはプロセステーブルを食いつぶし、あまりに多い数を放置するとプロセス生成が失敗する。
As long as a zombie is not removed from the system via a wait, it will consume a slot in the kernel process table, and if this table fills, it will not be possible to create further processes
引用元: man page of wait
そのため、親プロセスは子プロセスを適切にハンドリングして Zombie を成仏させる義務がある。成仏させるには、さまざまな方法がある。
- 親プロセスで wait/waitpid/waitid して子の終了を待つ
- 子プロセスが死んだときに親プロセスに送信されるシグナル(SIGCHLD)をキャッチして wait/waitpid/waitid する
- double fork する
- 親プロセスで sigactionを使って SA_NOCLDWAIT フラグを設定する
systemd では、 src/activate/activate.c#install_chld_handler で、SIGCHLD シグナルをキャッチして waitid(P_ALL, 0, &si, WEXITED | WNOHANG); を実行している。また systemd をリトライしたりサーバを停止するときは、すべてのプロセスに SIGTERM を送ったあとに、子が死ぬまで sigtimedwait(mask, NULL, &ts); と waitpid(-1, NULL, WNOHANG); を繰り返して待機する(src/core/killall.c#broadcast_signal)。この仕組みがない場合、shutdown -r now でサーバ停止したときにプロセスが正しくクリーンアップされずに死ぬ可能性があり、DB データの更新中にプロセスが停止する、といったことが起きかねない。グレースフルシャットダウンを実現するためには、親プロセスとしての役割をきちんと果たす必要がある。
これらは Docker の pid=1 問題でも同様で、親プロセスが正しくハンドリングする責務がある。アプリケーション側でハンドリングできない場合のために、軽量な init コンテナも提供されている。
参考 Docker and the PID 1 zombie reaping problem
参考
最後に
今後は各スケジューラの詳細について調べたい。難しそー。