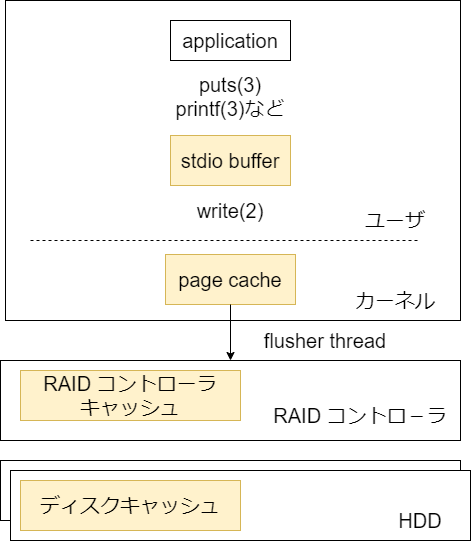
ファイルがディスクに書き込まれるまでの道のりをまとめた。
stdio buffer
write(2) を細かい単位で実行すると効率が悪い。
たとえば次のようなプログラムは、
#include <stdio.h>
#include <unistd.h>
int main() {
write(1, "a", 1);
write(1, "b", 1);
}
write の度にシステムコールが実行される。
]# strace -e write ./main
write(1, "a", 1a) = 1
write(1, "b", 1b) = 1
+++ exited with 0 +++
そこで、ある程度書き込み要求をまとめて write(2) を実行するためのバッファが存在する。puts や printf といった stdio の関数を実行するとバッファに蓄積されていき、あるタイミングで write(2) が実行される。たとえば次のようなプログラムは、
#include <stdio.h>
#include <unistd.h>
int main() {
fwrite("a", 1, 1, stdout);
fwrite("b", 1, 1, stdout);
}
複数の fwrite 呼び出しをまとめて、 write(2) を実行する。
]# strace -e write ./main
write(1, "ab", 2ab) = 2
+++ exited with 0 +++
バッファリングのモード
バッファリングにはいくつかのモードがある。glibc のデフォルトは完全バッファリングだが、出力先が tty の場合は行バッファリングになる。また setvbuf(3) で変更できる。
参考 12.20.1 Buffering Concepts
| モード | 内容 |
|---|---|
| 完全バッファリング | バッファが埋まったら出力する |
| 行バッファリング | バッファが埋まらなくても改行コードがあったら出力する |
| バッファリングなし | バッファリングしない |
性能
自分の手元環境で動作確認すると、
#include <stdio.h>
#include <unistd.h>
int main() {
int i = 0;
for (i = 0; i < 10000000; i++) {
// 検証ごとにどちらかを有効にする
// write(1, "a", 1);
// fwrite("a", 1, 1, stdout);
}
}
小さな書き込みを 10000000 回繰り返すと、write(2) と fwrite(3) で 20 倍程度の差が出た。
// write(2)
]# time ./main > /dev/null
real 0m4.135s
user 0m2.467s
sys 0m1.655s
// fwrite(3)
]# time ./main > /dev/null
real 0m0.169s
user 0m0.167s
sys 0m0.002s
上記結果を見ると fwrite(3) では user と sys のどちらも下がっている。検証前はバッファリングするとユーザ空間の処理が増えて(user が増える)カーネルの処理が減る(sys が減る)と思ってたので、これは意外だった。perf record 取ってみたところ、write(2) でユーザ空間上のオーバーヘッド(__GI___libc_write)があるっぽい。fwrite(3) だとバッファリングのための処理(_IO_fwrite)が増えてはいるが、それよりも write(2) のオーバーヘッド(__GI___libc_write)が減ったことがパフォーマンス上の効果が大きいのではないかと思う。
]# perf record ./main
]# perf report
// write(2)
57.01% main libc-2.28.so [.] __GI___libc_write
19.44% main [kernel.kallsyms] [k] do_syscall_64
2.97% main [kernel.kallsyms] [k] __fget_light
2.83% main [kernel.kallsyms] [k] selinux_file_permission
1.86% main [kernel.kallsyms] [k] vfs_write
1.84% main [kernel.kallsyms] [k] fsnotify
1.56% main [kernel.kallsyms] [k] ksys_write
1.52% main [kernel.kallsyms] [k] __audit_syscall_exit
1.12% main [kernel.kallsyms] [k] __audit_syscall_entry
]# perf record ./main
]# perf report
// fwrite(3)
53.21% main libc-2.28.so [.] _IO_fwrite
28.68% main libc-2.28.so [.] _IO_file_xsputn@@GLIBC_2.2.5
10.38% main main [.] main
3.40% main libc-2.28.so [.] __memmove_avx_unaligned_erms
2.64% main libc-2.28.so [.] __mempcpy_avx_unaligned_erms
0.57% main libc-2.28.so [.] __GI___libc_write
0.19% main [kernel.kallsyms] [k] security_file_permission
0.19% main [kernel.kallsyms] [k] selinux_file_permission
0.19% main [kernel.kallsyms] [k] syscall_slow_exit_work
0.19% main [kernel.kallsyms] [k] syscall_trace_enter
0.19% main libc-2.28.so [.] _dl_addr
0.19% main libc-2.28.so [.] 0x0000000000021844
またバッファサイズによる性能差についても雑に調べた。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
// バッファサイズを変更する
#define BUFFER_SIZ 10
int main(int argc, char *argv[]) {
char buf[BUFFER_SIZ];
FILE *fd;
if ( ( fd = fopen("out.txt", "w") ) == NULL) {
perror("fopen");
return 1;
}
if (setvbuf(fd, buf, _IOFBF, sizeof(buf)) != 0) {
perror("setvbuf");
return 1;
}
long i = 0;
for (i = 0; i < 1000000000; i++) {
fwrite("a", 1, 1, fd);
}
}
バッファが少なすぎると非効率だが、多すぎてもたいした効果が得られないことがわかった。
| バッファサイズ | real | user | sys |
|---|---|---|---|
| 10 | 2m30.928s | 1m5.036s | 1m25.414s |
| 100 | 0m28.440s | 0m18.762s | 0m9.587s |
| 1000 | 0m14.413s | 0m13.561s | 0m0.802s |
| 4096(デフォルト) | 0m13.608s | 0m13.184s | 0m0.380s |
| 8192 | 0m13.537s | 0m13.184s | 0m0.307s |
| 409600 | 0m13.297s | 0m12.986s | 0m0.267s |
glibc のバッファサイズのデフォルトは基本的にブロックサイズと同じだが、性能検証した上でチューニングする余地はあると思う。
バッファサイズのデフォルトについて
setvbuf の man を読むと BUFSIZ というマクロがある。これは setvbuf で指定するバッファサイズのデフォルト値。
The setbuffer() function is the same, except that the size of the buffer is up to the caller, rather than being determined by the default BUFSIZ.
CentOS 8 の glibc-2.28-101.el8.x86_64 だと 8192 だった。
#include <stdio.h>
int main(void) {
printf("BUFSIZ : %d\n", BUFSIZ);
}
]# ./main
BUFSIZ : 8192
setvbuf を利用しないときは BUFSIZ がバッファサイズのデフォルト値だと期待したが、そうではなかった。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
FILE *fd;
if ( ( fd = fopen("out.txt", "w") ) == NULL) {
perror("fopen");
return 1;
}
long i = 0;
for (i = 0; i < 1000000000; i++) {
fwrite("a", 1, 1, fd);
}
}
実行すると 4096 ごとに書き込んでいるので、バッファサイズが 4096 だと考えられる。
]# strace -e write ./main 2>&1 | head
write(3, "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"..., 4096) = 4096
write(3, "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"..., 4096) = 4096
write(3, "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"..., 4096) = 4096
write(3, "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"..., 4096) = 4096
バッファサイズがどう決まるかについて glibc のソースコードを gdb でデバッグして調べたところ、次のようになっていた。
バッファサイズが指定されていれば、それを利用する
バッファサイズが指定されていなければ、初回の fwrite 時にバッファを確保する
- 書き込み対象のファイルを stat してブロックサイズを調べる
- ブロックサイズ < BUFSIZ ならば ブロックサイズ をバッファサイズにする(かなり前(1995年)からブロックサイズに合わせてた様子。96aa2d94a2355cdc55c96e808d14a0e7f2ebe77d)
- ブロックサイズ >= BUFSIZ ならば BUFSIZ をバッファサイズにする(たまにとんでもなくでかいブロックサイズを返すネットワークファイルシステムが存在する対策らしい。libio: Limit buffer size to 8192 bytes [BZ #4099])
詳細に興味がある方は、backtrace を載せておくので該当コードを調べてください。
(gdb) bt
#0 __GI__IO_file_doallocate (fp=0x6022a0) at filedoalloc.c:78
#1 0x00007ffff7a90b70 in __GI__IO_doallocbuf (fp=fp@entry=0x6022a0) at libioP.h:838
#2 0x00007ffff7a8fdd8 in _IO_new_file_overflow (f=0x6022a0, ch=-1) at fileops.c:749
#3 0x00007ffff7a8ef6f in _IO_new_file_xsputn (n=1, data=<optimized out>, f=0x6022a0) at libioP.h:838
#4 _IO_new_file_xsputn (f=0x6022a0, data=<optimized out>, n=1) at fileops.c:1201
#5 0x00007ffff7a83e2c in __GI__IO_fwrite (buf=0x400758, size=1, count=1, fp=0x6022a0) at libioP.h:838
#6 0x000000000040068d in main (argc=1, argv=0x7fffffffdb68) at main.c:13
注意点
バッファリングした場合、意図せずユーザ空間で詰まることがある。例えば次のようなプログラムを実行すると、
#include <stdio.h>
#include <unistd.h>
int main(int argc, char* argv[]) {
fwrite("a", 1, 1, stdout);
fwrite("b", 1, 1, stdout);
sleep(10);
}
fwrite が 2 回呼び出された時点ではバッファが溜まってないので write(2) されない。
]# strace -e write,nanosleep ./main
nanosleep({tv_sec=10, tv_nsec=0},
0x7fff83d42a30) = 0
write(1, "ab", 2ab) = 2
+++ exited with 0 +++
sleep よりも前に write(2) したい場合は、明示的に fflush を呼び出すと、
#include <stdio.h>
#include <unistd.h>
int main(int argc, char* argv[]) {
fwrite("a", 1, 1, stdout);
fwrite("b", 1, 1, stdout);
fflush(stdout);
sleep(10);
}
バッファリングした内容を強制的に write(2) できる。
]# strace -e write,nanosleep ./main
write(1, "ab", 2ab) = 2
nanosleep({tv_sec=10, tv_nsec=0}, 0x7fff443ca300) = 0
+++ exited with 0 +++
なお、アプリケーション終了まで fflush されない場合は、 exit ハンドラ内でフラッシュされる。そのため _exit(2) などで停止すべきではない。
ページキャッシュ
write システムコール実行時にディスクへは書き込みせずに、メモリ上のデータ(ページキャッシュ)だけを更新する。その後 flusher thread が適当なタイミング(定期的にだったり、 Dirty ページのしきい値を超えたらだったり)でディスクに書き込む。詳細は以前調べた。
Linux ファイルシステム 徹底入門 - SIerだけど技術やりたいブログwww.kimullaa.com
ページキャッシュの利用は open 時のフラグで次のように制御できる。また O_SYNC/O_DSYNC のほかに、 fsync/fdatasync を用いて特定のタイミングで同期する方法もある。
| open 時のフラグ | 内容 |
|---|---|
| O_DIRECT | ページキャッシュをバイパスする ※ |
| O_SYNC | write(2) 時に書き込みデータとメタデータをディスクに同期する |
| O_DSYNC | write(2) 時に書き込みデータだけはディスクに同期する |
※ たとえば DB など、アプリケーションに独自のキャッシュがある場合にはバイパスすることが多い。 ただし自分がよく使う PostgreSQL はこれに該当せず、ページキャッシュを使いつつ動作する。
性能
dd で雑に性能を測ると、次のようになった。
| パターン | 転送レート |
|---|---|
| フラグなし | 92.9 MB/s |
| O_DIRECT | 4.9 MB/s |
| O_SYNC | 157 kB/s |
| O_DSYNC | 144 kB/s |
| fsync | 85.7 MB/s |
| fdatasync | 87.7 MB/s |
表から、次のことがわかる。
- フラグなしはメモリ上に書き込むだけなので圧倒的に早い
- dd の場合は fsync/fdatasync は最後にまとめてディスクに同期するだけなので、フラグなしと遜色ないレベルで早い
- 次いで O_DIRECT がページキャッシュをバイパスする分 O_SYNC や O_DSYNC より早い
// フラグなし
]# dd if=/dev/zero of=./out count=10000 bs=512
10000+0 レコード入力
10000+0 レコード出力
5120000 bytes (5.1 MB, 4.9 MiB) copied, 0.0551348 s, 92.9 MB/s
// O_DIRECT の場合
]# dd if=/dev/zero of=./out count=10000 bs=512 oflag=direct
10000+0 レコード入力
10000+0 レコード出力
5120000 bytes (5.1 MB, 4.9 MiB) copied, 1.05219 s, 4.9 MB/s
// O_SYNC の場合
]# dd if=/dev/zero of=./out count=10000 bs=512 oflag=sync
10000+0 レコード入力
10000+0 レコード出力
5120000 bytes (5.1 MB, 4.9 MiB) copied, 32.5777 s, 157 kB/s
// O_DSYNC の場合
]# dd if=/dev/zero of=./out count=10000 bs=512 oflag=dsync
10000+0 レコード入力
10000+0 レコード出力
5120000 bytes (5.1 MB, 4.9 MiB) copied, 35.5238 s, 144 kB/s
// fsync の場合
]# dd if=/dev/zero of=./out count=10000 bs=512 conv=fsync
10000+0 レコード入力
10000+0 レコード出力
5120000 bytes (5.1 MB, 4.9 MiB) copied, 0.0597102 s, 85.7 MB/s
// fdatasync の場合
]# dd if=/dev/zero of=./out count=10000 bs=512 conv=fdatasync
10000+0 レコード入力
10000+0 レコード出力
5120000 bytes (5.1 MB, 4.9 MiB) copied, 0.0583977 s, 87.7 MB/s
結論としては、書き込みのたびにディスクに同期してるとコストが半端じゃないことがわかる。
なお O_SYNC と O_DSYNC でほぼ差がなかったが(というかなんなら O_SYNC のほうが早いが)、直感的には O_DSYNC のほうが書き込みを保証する範囲が狭いぶん早くなる気がする。メインラインの Linux カーネルの 2.6.32 以前では O_DSYNC がまともに実装されていなかったという話もあったようだが、現在はまともに実装されてるよう。じゃあなんで O_SYNC と O_DSYNC の速度差がほぼないんだろうかと思って調べたがわかりませんでした…誰が教えてください。
参考 Linux Kernel Watch 12月版 ネットワークアクセス権も放棄せよ
参考 man open(2)
参考 implement posix O_SYNC and O_DSYNC semantics
RAID コントローラキャッシュ
ハードウェアで RAID 構成を組むときは RAID コントローラにキャッシュが存在することが多い。たとえば HP の Smart アレイのカタログスペックによると、キャッシュが存在しないものから 4GB あるものまでいろいろあるらしい。\
書き込み方式は write-through と write-back の 2 つある。
| 方式 | 内容 |
|---|---|
| write-through | ハードディスクに書き込んだら完了を返す。 |
| write-back | RAID コントローラのキャッシュメモリに書き込んだら完了を返す。ディスクへの書き込みは遅延実行する。 |
write-back のほうがパフォーマンスは出るが、電源断が起きるとデータが消えてしまう。そのためバッテリ内蔵のものを使うか、UPS 装置などと組み合わせることで不慮の電源断を回避する必要がある。
参考 Document Display | HPE Support Center
参考 https://h50146.www5.hpe.com/lib/products/servers/proliant/manuals/882375-193_ja.pdf
設定はストレージ製品ごとに提供されるコマンドラインツールを利用する。HP Smart アレイの場合は Smart Storage Administrator のコマンドラインツールで行うらしいが、そんなものはご自宅にないので動作確認はできなかった。詳細は HP ProLiant サーバー - Smart Storage Administrator (SSA) CLI での操作方法 (オンライン)を参照してください。
また HP の Smart アレイには、SSD と HDD の性能差を利用して SSD をキャッシュとして利用する技術(HP Smart Cache)もあるらしい。ソフトウェアで実現する方法として Linux にも dm-cache や bcache があるらしい。
参考 http://www.pt-solutions.com/pdf/HPsmartcache.pdf
参考 https://www8.hp.com/jp/ja/hp-news/press-release.html?id=1383655
ディスクキャッシュ
HDD 自体にあるキャッシュ。現状ストレージに関する知識がほぼないので、詳細は以下を参照してください。
参考 https://incarose86.hatenadiary.org/entry/20110716/1310840890
参考 Red Hat Enterprise Linux 7 ストレージ管理ガイド
最後に
書き込みを高速化するために、複数のレイヤで高速化の仕組みがあった。すごい。