Linux システムコールについて調べたことをまとめる。システムコールの仕組みを理解すると、 OS とアプリケーションがどのように連携して動いているのかを理解できるようになります。
システムコールは CPU に依存する処理が多いため、 x86_64 に絞ります。
検証環境
]# cat /etc/redhat-release
CentOS Linux release 8.0.1905 (Core)
]# uname -a
Linux localhost.localdomain 4.18.0-80.11.2.el8_0.x86_64 #1 SMP Tue Sep 24 11:32:19 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
]# cat /proc/cpuinfo | head
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R) Core(TM) i5-4690 CPU @ 3.50GHz
stepping : 3
microcode : 0xffffffff
cpu MHz : 3499.998
cache size : 6144 KB
physical id : 0
システムコールとは
アプリケーションは OS 上で動作する。アプリケーションが好き勝手にデバイス操作やその他のアプリケーションに影響を与える操作を実行できると危ない。
そのためユーザと OS で権限を分け、デバイス操作やプロセス操作を OS が一元管理する。この機能を提供している OS の中核部分をカーネルと呼び、この機能の実行依頼をシステムコールと呼ぶ。
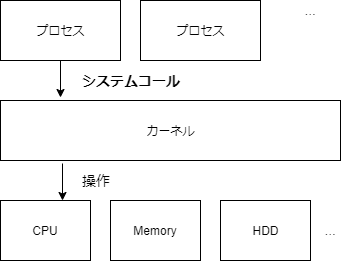
システムコール(処理を依頼すること)によって、次を実現できる。
- デバイス操作コードの共通化
- デバイスの排他制御
- ユーザフレンドリーな API の提供(ex. Linux ではほとんどがファイルとして扱える)
- 実行可能なルーチンの制限
- 不正な要求のチェック
次からは、どのようにシステムコールが動作するかを説明する。
システムコールの利用方法
システムコールはつまりカーネル関数の呼び出しだが、通常の関数と同じ方法ではカーネル関数は呼び出せない。
なぜなら、関数呼び出しとは(詳細を端折ると) cpu の命令ポインタに関数アドレスが設定されることだが、ユーザ空間とカーネル空間はメモリ空間が異なるため、ユーザアプリケーションがカーネルのメモリ領域にアクセスできないから。
Linux メモリ管理 徹底入門(プロセス編) - SIerだけど技術やりたいブログwww.kimullaa.com
そのため、割込みやsyscall命令を利用したシステムコール専用の手続きが用意されている。
ABI
システムコールはユーザ空間に対して ABI (バイナリレベルでの呼び出し規約)を定めている。そのため、システムコールの呼び出し前にはレジスタなどを決められた通りに設定する必要がある。例えば、 x86_64 だと、arch/x86/entry/entry_64.Sで次のように記載されている。
* Registers on entry:
* rax system call number
* rcx return address
* r11 saved rflags (note: r11 is callee-clobbered register in C ABI)
* rdi arg0
* rsi arg1
* rdx arg2
* r10 arg3 (needs to be moved to rcx to conform to C ABI)
* r8 arg4
* r9 arg5
* (note: r12-r15, rbp, rbx are callee-preserved in C ABI)
参考 arch/x86/entry/entry_64.S
参考 Wikipedia x86-64 calling conventions
参考 Wikipedia 呼出規約
実行してみる
syscallを利用したシステムコールの呼び出しをアセンブリで実施してみる。
main.asm
; 変数定義
section .data
MESSAGE: db "hello world",0x0A
; 現在のアドレス位置 - MESSAGEのアドレス位置 = MESSAGE の長さ
MESSAGE_LENGTH equ $ - MESSAGE
section .text
global _start
_start:
mov rax, 1 ; write のシステムコール番号
mov rdi, 1 ; stdout
mov rsi, MESSAGE
mov rdx, MESSAGE_LENGTH
syscall
mov rax, 60 ; exit のシステムコール番号
mov rdi, 0 ; exit code
syscall
これを実行すると、標準出力にhello worldと表示される。
]# nasm -felf64 main.asm
]# ld -o main main.o
]# ./main
hello world
なお、システムコール番号は次で確認できる。
参考 Linuxのシステムコール番号を探す
]# cat /usr/include/asm/unistd_64.h | grep write
#define __NR_write 1
...
]# cat /usr/include/asm/unistd_64.h | grep exit
#define __NR_exit 60
...
念のため、straceを利用してシステムコールが呼び出されていることを確認する。
]# strace ./main
execve("./main", ["./main"], 0x7ffd039a47e0 /* 35 vars */) = 0
write(1, "hello world\n", 12hello world
) = 12
exit(0) = ?
+++ exited with 0 +++
リングプロテクション
さきほどシステムコールを通してカーネル関数を呼び出せることを説明した。それでは、カーネル関数をユーザ空間に全て実装し直せば、システムコールは不要になるような気もする。しかし、これはリングプロテクションで防がれている。
リングプロテクションは アクセスレベルを制御する CPU の仕組みで、下図のように階層構造になっている。レベルごとに実行可能な命令に差をつけ、なおかつ、システムコール時にだけレベルを切り替えることで、ユーザからの意図しない命令実行を防ぐことができる。
引用元: Wikipedia リングプロテクション

上記のうち、どのレベルまで使うかは OS に依存する。Linux では Ring 0 と Ring 3 のみを利用するが Multics という OS は 8 レベルも定義している。Ring 0 をカーネルモード、 Ring 3 をユーザモードという。
参考 Wikipedia リングプロテクション
次のアセンブリを用意し、意図しない操作を防げることを確認する。
section .text
global _start
_start:
hlt
mov rax, 60 ; exit system call
mov rdi, 0 ; exit code
syscall
hlt はユーザモードだと許可されない命令。
The HLT instruction is a privileged instruction.
引用元: IntelR 64 and IA-32 Architectures Software Developer’s Manual
実行すると Segmentation faultが発生してプロセスが強制終了する。
]# nasm -felf64 main.asm
]# ld -o main main.o
]# ./main
Segmentation fault (コアダンプ)
このとき/var/log/messagesに、general protectionという一般保護違反のメッセージが表示される。
Jan 3 00:31:31 localhost kernel: traps: main[9016] general protection ip:400080 sp:7ffd8de8dc60 error:0 in main[400000+1000]
Jan 3 00:31:31 localhost systemd[1]: Started Process Core Dump (PID 9017/UID 0).
Jan 3 00:31:31 localhost systemd-coredump[9018]: Process 9016 (main) of user 0 dumped core.#012#012Stack trace of thread 9016:#012#0 0x0000000000400080 _start (/root/kernel/main)
上記から、意図しないリソース操作をユーザ空間からは行えないことがわかる。
ユーザモード
当然だが、ユーザに許可された命令の範囲であれば例外は発生しない。例えば jmp 命令を利用した次のプログラムを作成する。
section .text
global _start
_start:
_loop: ; 無限ループ
jmp _loop
mov rax, 60 ; exit system call
mov rdi, 0 ; exit code
syscall
これを実行すると、ユーザモードで無限ループする。
]# nasm -felf64 main.asm
]# ld -o main main.o
]# ./main
^C
そのため、1 プロセスが 1 コアをほぼ消費する。またユーザモードのため、 CPU 処理時間は %user に計上される。sar で確認した結果は次の通り。
]# LANG=C; sar -P ALL 10
Linux 4.18.0-80.11.2.el8_0.x86_64 (localhost.localdomain) 01/03/20 _x86_64_ (4 CPU)
07:35:12 CPU %user %nice %system %iowait %steal %idle
07:35:22 all 0.00 0.00 0.07 0.00 0.00 99.92
07:35:22 0 0.00 0.00 0.20 0.00 0.00 99.80
07:35:22 1 0.00 0.00 0.10 0.00 0.00 99.90
07:35:22 2 0.00 0.00 0.00 0.00 0.00 100.00
07:35:22 3 0.00 0.00 0.00 0.00 0.00 100.00
<<< ここで ./main を実行する >>>
07:35:22 CPU %user %nice %system %iowait %steal %idle
07:35:32 all 18.77 0.00 0.15 0.00 0.00 81.08
07:35:32 0 0.00 0.00 0.00 0.00 0.00 100.00
<<< %user が増加する >>>
07:35:32 1 75.15 0.00 0.40 0.00 0.00 24.45
07:35:32 2 0.00 0.00 0.10 0.00 0.00 99.90
07:35:32 3 0.00 0.00 0.10 0.00 0.00 99.90
07:35:32 CPU %user %nice %system %iowait %steal %idle
07:35:42 all 24.83 0.00 0.18 0.03 0.00 74.97
07:35:42 0 0.00 0.00 0.00 0.10 0.00 99.90
<<< %user で使い切る >>>
07:35:42 1 99.30 0.00 0.70 0.00 0.00 0.00
07:35:42 2 0.00 0.00 0.00 0.00 0.00 100.00
07:35:42 3 0.00 0.00 0.00 0.00 0.00 100.00
^C
スタック
スタックはプロセス用とカーネル用でそれぞれ異なり、カーネルスタックはアクティブなプロセスごとに用意される。スタックは SYSCALL 実行時に TSS(struct tss_struct) に設定されたアドレスに切り替える(IntelR 64 and IA-32 Architectures Software Developer’s Manual を読むと、CPU の機能として SYSCALL 時に スタックポインタを切り替える機能はあるようだけど、x86_64 では Linux カーネル自身がスタックの切り替えを行っているようにみえる)。なおシステムコール実行中は、呼び出し元プロセスのスタックは変更されない。

カーネルスタックとプロセス用のスタックが存在することを bpftrace で確認する。
#include <unistd.h>
void func3() {
write(1, "hello world\n", 12);
}
void func2() {
func3();
}
void func1() {
func2();
}
int main(void) {
func1();
// 終了したプロセスの ustack がシンボル表示されないバグがあるため sleep する
// https://github.com/iovisor/bpftrace/issues/246
sleep(10);
}
上記をコンパイルして実行し、 bpftrace(このころは bpftrace は CentOS 8 の yum リポジトリでパッケージが提供されてなかったので自分でビルドした) でユーザスタックとカーネルスタックを出力する。
出力から分かる通り、スタックはそれぞれ異なる。
]# bpftrace -e 'kprobe:ksys_write /comm == "a.out" / { printf("====user====\n%s\n=====kernel====\n%s\n", ustack(), kstack()); }'
Attaching 1 probe...
====user====
write+24
func2+14
func1+14
main+14
__libc_start_main+243
0x5541f689495641d7
=====kernel====
ksys_write+1
do_syscall_64+91
entry_SYSCALL_64_after_hwframe+101
システムコールの実装を確認する
今回の例ではシステムコール呼び出しにsyscallを利用した。なぜsyscallでシステムコールが実行できるかというと、
- syscall 命令は事前に登録されたアドレスを実行する(rip レジスタに設定する)命令であり、
参考 SYSCALL - Fast System Call
引用元: IntelR 64 and IA-32 Architectures Software Developer’s Manual
- カーネル起動時(
init/main.c#start_kernel())にハンドラが登録されているため。
ハンドラの登録はarch/x86/kernel/cpu/common.c の syscall_init()で行う。ここでは、entry_SYSCALL_64という関数を登録している。
void syscall_init(void)
{
wrmsr(MSR_STAR, 0, (__USER32_CS << 16) | __KERNEL_CS);
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);
...
entry_SYSCALL_64はarch/x86/entry/entry_64.S にある。ここでは、カーネル空間にスイッチしてレジスタを整えて(スタックポインタを切り替えるなど) do_syscall_64を実行している。
ENTRY(entry_SYSCALL_64)
UNWIND_HINT_EMPTY
/*
* Interrupts are off on entry.
* We do not frame this tiny irq-off block with TRACE_IRQS_OFF/ON,
* it is too small to ever cause noticeable irq latency.
*/
swapgs
/* tss.sp2 is scratch space. */
movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2)
SWITCH_TO_KERNEL_CR3 scratch_reg=%rsp
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(cpu_tss_rw + TSS_sp2) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx
GLOBAL(entry_SYSCALL_64_after_hwframe)
pushq %rax /* pt_regs->orig_ax */
IBRS_ENTRY
PUSH_AND_CLEAR_REGS rax=$-ENOSYS
TRACE_IRQS_OFF
/* IRQs are off. */
movq %rax, %rdi
movq %rsp, %rsi
call do_syscall_64 /* returns with IRQs disabled */
do_syscall_64 は arch/x86/entry/common.c にある。ここでは、ユーザがraxに設定したシステムコール番号をもとにsys_call_tableからハンドラを取り出して実行している。
__visible void do_syscall_64(unsigned long nr, struct pt_regs *regs)
{
struct thread_info *ti;
enter_from_user_mode();
local_irq_enable();
ti = current_thread_info();
if (READ_ONCE(ti->flags) & _TIF_WORK_SYSCALL_ENTRY)
nr = syscall_trace_enter(regs);
/*
* NB: Native and x32 syscalls are dispatched from the same
* table. The only functional difference is the x32 bit in
* regs->orig_ax, which changes the behavior of some syscalls.
*/
nr &= __SYSCALL_MASK;
if (likely(nr < NR_syscalls)) {
nr = array_index_nospec(nr, NR_syscalls);
regs->ax = sys_call_table[nr](regs);
}
syscall_return_slowpath(regs);
}
なお、sys_call_tableはarch/x86/um/sys_call_table_64.cにある。include 対象の<asm/syscalls_64.h>は、ビルド時に生成されるらしい。
参考 POSTD Linuxシステムコール徹底ガイド
参考 システムコールの呼び出し方を調べた
const sys_call_ptr_t sys_call_table[] ____cacheline_aligned = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};
ということで、上記のような流れでシステムコールが実行される。
ユーザプロセスに戻るときは、sysretを利用し、上記と逆の操作(メモリをユーザ空間に切り替えて、退避していたシステムコール実行前の値をripレジスタに設定する)を行う。
今回はsyscallだけを見たが、レガシーな環境ではint 0x80割込みを利用する。詳細は次が詳しい。
参考 POSTD Linuxシステムコール徹底ガイド
システムコールには様々な呼び出し方法があるので、glibc では vsyscall を利用して最適な呼び出し方の実装を後で選択できるようにしてるらしい。64 bit でも同様の仕組みなのかは調べきれてないので、今後調べる。
参考 vsyscall
システムコールは遅い?
システムコールは遅いと言われているが、どれくらい遅いのかを試してみる。
そのために、何もしないシステムコールを作成して実行時間を比較する。システムコールの追加方法は次のサイトを参考にした。
参考 POSTD チュートリアル - システムコールの書き方
参考 The Linux Kernel Adding a New System Call
実装に使った spec ファイルは次のとおり。
--- /root/rpmbuild/SPECS/kernel.spec.org 2019-12-14 02:10:44.617212554 -0500
+++ /root/rpmbuild/SPECS/kernel.spec 2020-01-03 14:50:28.448410919 -0500
@@ -30,13 +30,13 @@
%global zipsed -e 's/\.ko$/\.ko.xz/'
%endif
-# define buildid .local
+%define buildid .local
%define rpmversion 4.18.0
%define pkgrelease 80.11.2.el8_0
# allow pkg_release to have configurable %%{?dist} tag
-%define specrelease 80.11.2%{?dist}
+%define specrelease 80.11.9999%{?dist}
%define pkg_release %{specrelease}%{?buildid}
@@ -418,6 +418,8 @@
Patch1001: debrand-rh_taint.patch
Patch1002: debrand-rh-i686-cpu.patch
+Patch99999: noop.patch
+
# empty final patch to facilitate testing of kernel patches
Patch999999: linux-kernel-test.patch
@@ -880,6 +882,7 @@
ApplyOptionalPatch debrand-single-cpu.patch
ApplyOptionalPatch debrand-rh_taint.patch
ApplyOptionalPatch debrand-rh-i686-cpu.patch
+ApplyOptionalPatch empty.patch
# END OF PATCH APPLICATIONS
パッチファイル(noop.patch)は次のとおり。
diff -uprN kernel/sys.c kernel/sys.c
--- a/kernel/sys.c 2020-01-03 15:22:53.855484230 -0500
+++ b/kernel/sys.c 2020-01-03 15:23:19.640531186 -0500
@@ -2647,3 +2647,8 @@ COMPAT_SYSCALL_DEFINE1(sysinfo, struct c
return 0;
}
#endif /* CONFIG_COMPAT */
+
+SYSCALL_DEFINE0(noop)
+{
+ return 0;
+}
diff -uprN arch/x86/entry/syscalls/syscall_64.tbl arch/x86/entry/syscalls/syscall_64.tbl
--- a/arch/x86/entry/syscalls/syscall_64.tbl 2020-01-03 13:57:25.331014696 -0500
+++ b/arch/x86/entry/syscalls/syscall_64.tbl 2020-01-03 13:32:46.545448072 -0500
@@ -386,3 +386,4 @@
545 x32 execveat __x32_compat_sys_execveat/ptregs
546 x32 preadv2 __x32_compat_sys_preadv64v2
547 x32 pwritev2 __x32_compat_sys_pwritev64v2
+548 common noop __x64_sys_noop
上記を利用し、カーネルをビルドして再起動する。
参考 CentOS 7: カーネルを再ビルドする
次のとおり、システムコールが実装されていることがわかる。
]# uname -r
4.18.0-80.11.9999.el8.local.x86_64
]# cat /proc/kallsyms | grep sys_noop
ffffffff974bdf50 T __ia32_sys_noop
ffffffff974bdf50 T __x64_sys_noop
ffffffff98d79ca0 t _eil_addr___x64_sys_noop
作成した noop システムコールを利用するアセンブリを用意する。
section .text
global _start
_start:
mov rcx, 0
_loop:
push rcx ; システムコール中にカーネルが rcx を別の用途に使って値を壊すから退避する
mov rax, 548
syscall ; syscallなし の場合は nop にする。古い呼び出し方法の int 0x80 も検証する。
pop rcx
inc rcx
cmp rcx, 100000000 ; 1億回繰り返す
jbe _loop
mov rax, 60 ; exit system call
mov rdi, 0 ; exit code
syscall
これを実行し、 time コマンドで測定する。
]# nasm -felf64 main.asm
]# ld -o main main.o
]# time ./main
測定結果は次のとおり。
| 項目 | syscall | int 0x80 | nop |
|---|---|---|---|
| real | 0m20.103s | 0m35.937s | 0m0.230s |
| user | 0m8.453s | 0m15.931s | 0m0.227s |
| sys | 0m11.536s | 0m17.148s | 0m0.001s |
かなりアバウトな計測だが、システムコールの実行有無で実行時間にかなり差が出ることがわかる。そして古い呼び出し方法(int 0x80)よりも新しい呼び出し方法(syscall)のほうが早いことがわかる。
また syscall を利用したシステムコールのオーバーヘッドは1 回あたり約 2x10^-7 sec (だいたい 100 ナノ秒)だとわかる(CPU バウンドな処理なので環境に強く依存するのであくまで参考値)。
また AMD 6 core の syscall では、 getpid システムコールで 231 サイクル消費するらしい。(CPU アーキテクチャや カーネルバージョンに依存するため参考値だが)
参考 Stony Brook University Interrupts and System Calls
ということで、システムコールはユーザモードで実行する命令と比べると遅い処理だとわかった。
vdso
vdso は軽量なシステムコールの実行方法。いくつかのシステムコール(gettimeofday や getpid など、誰が実行してもよいもの)は、カーネル空間へのコンテキストスイッチなしでシステムコールを実行できる。
“vDSO” (virtual dynamic shared object; 仮想動的共有オブジェクト) は、 カーネルが自動的にすべてのユーザー空間アプリケーションのアドレス空間にマッピングを行う小さな共有ライブラリである。
引用元 man page of vdso
概要や実装方法は 次が参考になる。
参考 gettimeofday(2) は VDSO によりユーザー空間で実行される
参考 POSTD Linuxシステムコール徹底ガイド
今回は vdso が syscall と比較してどの程度早いかを調べる。
次のように gettimeofday を利用するコードを用意する。
#include <sys/time.h>
#include <stddef.h>
int main(void) {
int i = 0;
struct timeval tv;
for( i = 0; i < 100000000; i++) {
gettimeofday(&tv, NULL);
}
}
これを gcc でコンパイルすると、linux-vdso.so.1がリンクされることがわかる。
]# gcc main.c
]# ldd a.out
linux-vdso.so.1 (0x00007fffd4fc6000)
libc.so.6 => /lib64/libc.so.6 (0x00007f291eb5b000)
/lib64/ld-linux-x86-64.so.2 (0x00007f291ef1f000)
実行すると、 syscall の 1/10 以下で実行できることがわかる。かなり早い。
]# time ./a.out
real 0m1.843s
user 0m1.693s
sys 0m0.002s
システムコールとライブラリ
今回はアセンブリを多用したが、通常は自分で書いたアセンブリでシステムコールなんて呼び出さずにライブラリを利用する。(C 言語であれば glibc)
引用元: Linux カーネルの徹底調査

glibc にはシステムコールとライブラリ関数の 2 種類ある。 (man(2) がシステムコールで man(3) がライブラリ関数)
参考 第2回 システムコールとライブラリ関数
システムコール
システムコールは、アセンブリ呼び出しをほぼそのまま C 言語から使えるようにしたもの。ただしアセンブリで記述したときと比べて CPU アーキテクチャごとの違いを隠蔽できる。(コンパイルし直せば他のアーキテクチャに移植できる。つまり API 互換。)
API で定義されたふるまいになれば実装方法は問わないので、システムコールと厳密に 1:1 に対応しているとは限らない。たとえば fork(2) は clone システムコールを呼び出しているし、exit(2) も exit_group システムコールを呼び出している。
参考 APIとかABIとかシステムコールとか
参考 man page of fork
参考 man page of exit
たいていの言語では(このアセンブリの記述とかCPUごとの差異を考えるのがめんどくさいからなのか)libcを使ってシステムコールを実行することが多いが、言語によっては libc の関数を使ってなかったりする。たとえば go言語は言語内で独自に実装してたりする。詳しくは以下を参照してください。
ライブラリ関数
ライブラリ関数は、もう少し高機能。
- 煩雑なシステムコール呼び出しをスマートなインタフェースにする
- 性能が出やすいように工夫(たとえば I/O のバッファリング)する
一般的にライブラリ関数のほうが便利なので、開発者はこちらを使うことが多い。 むしろ下手にシステムコールを呼び出すと意図しない動作になる(たとえば _exit(2) を使ったせいで終了時のフックが呼ばれない、など)可能性すらある。
参考書籍
さいごに
これらの知識は日常で必要になる場面は少ないですが、アプリケーションの裏側ではシステムコールが実行されています。見えないけれども、そこにあるのです。
つまり『May the System Call be with you.(システムコールと共にあれ)』1。
